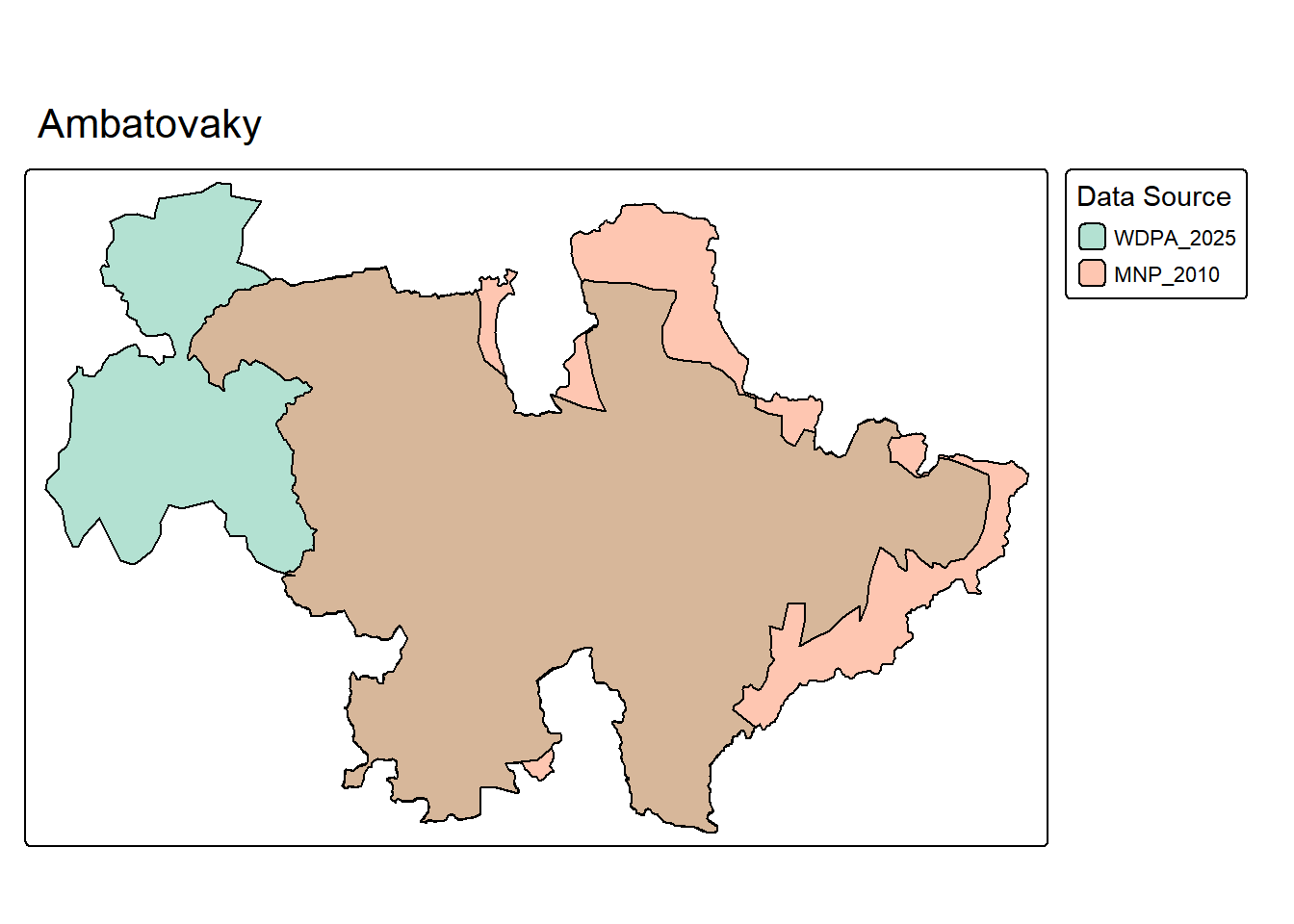
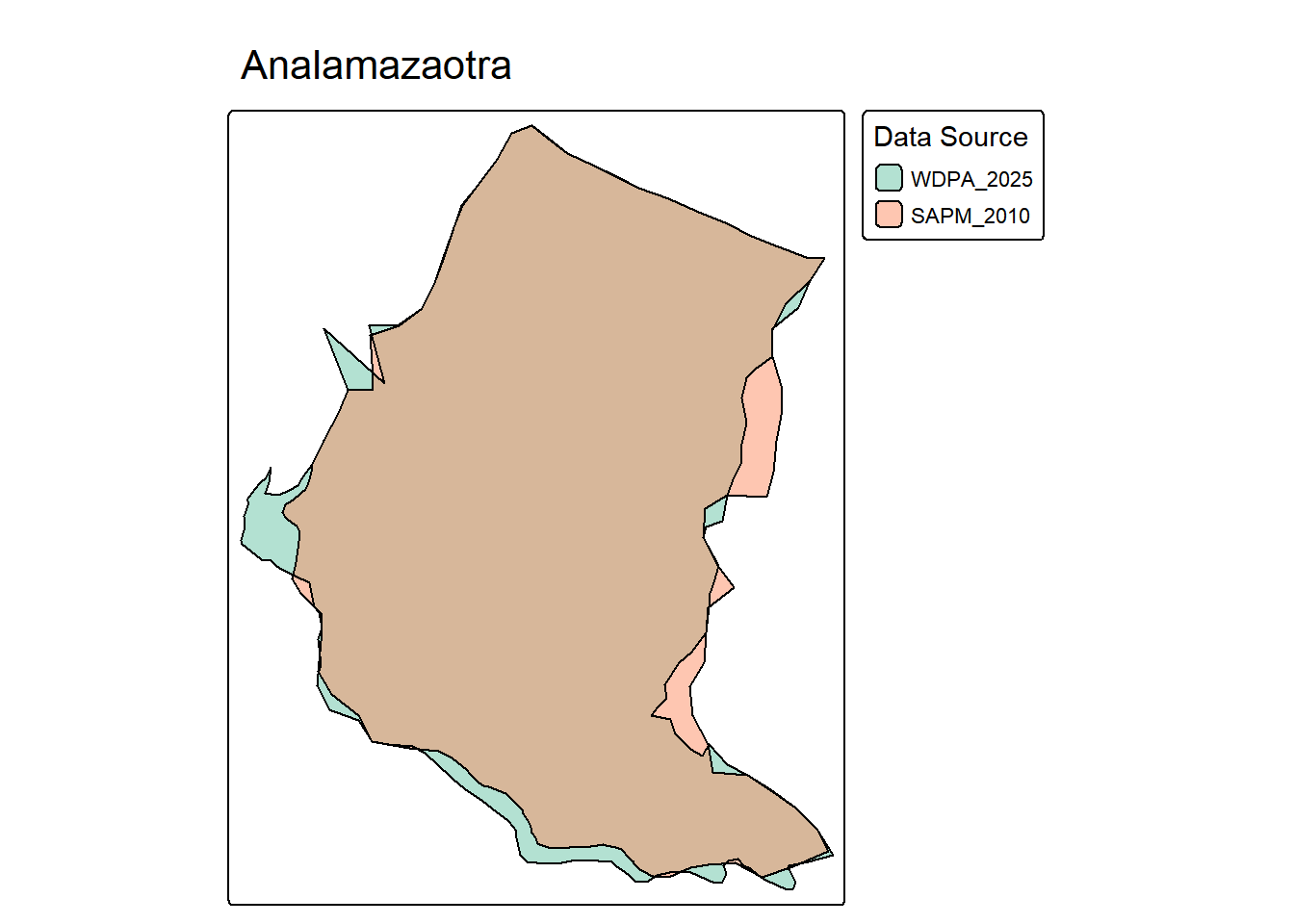
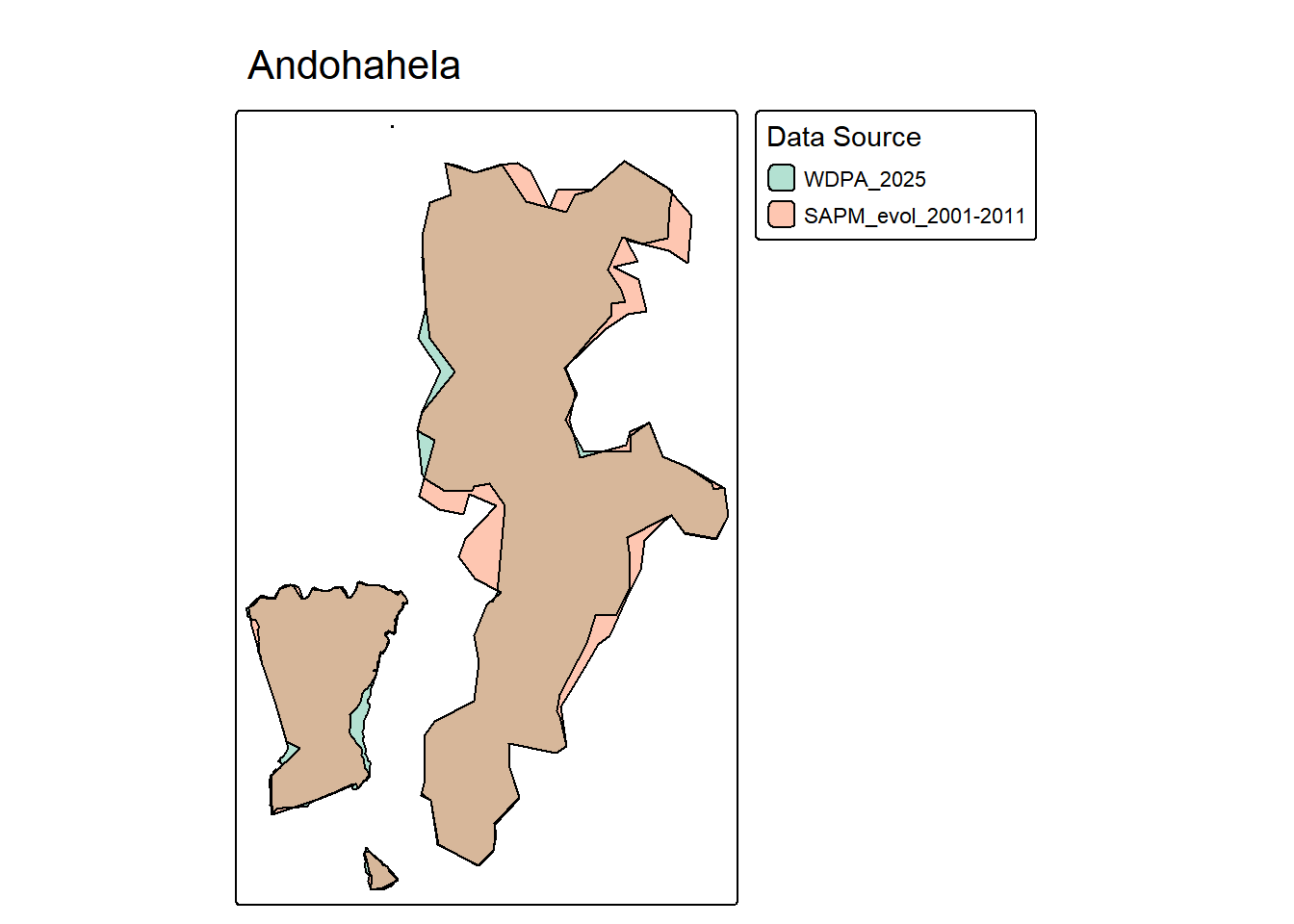
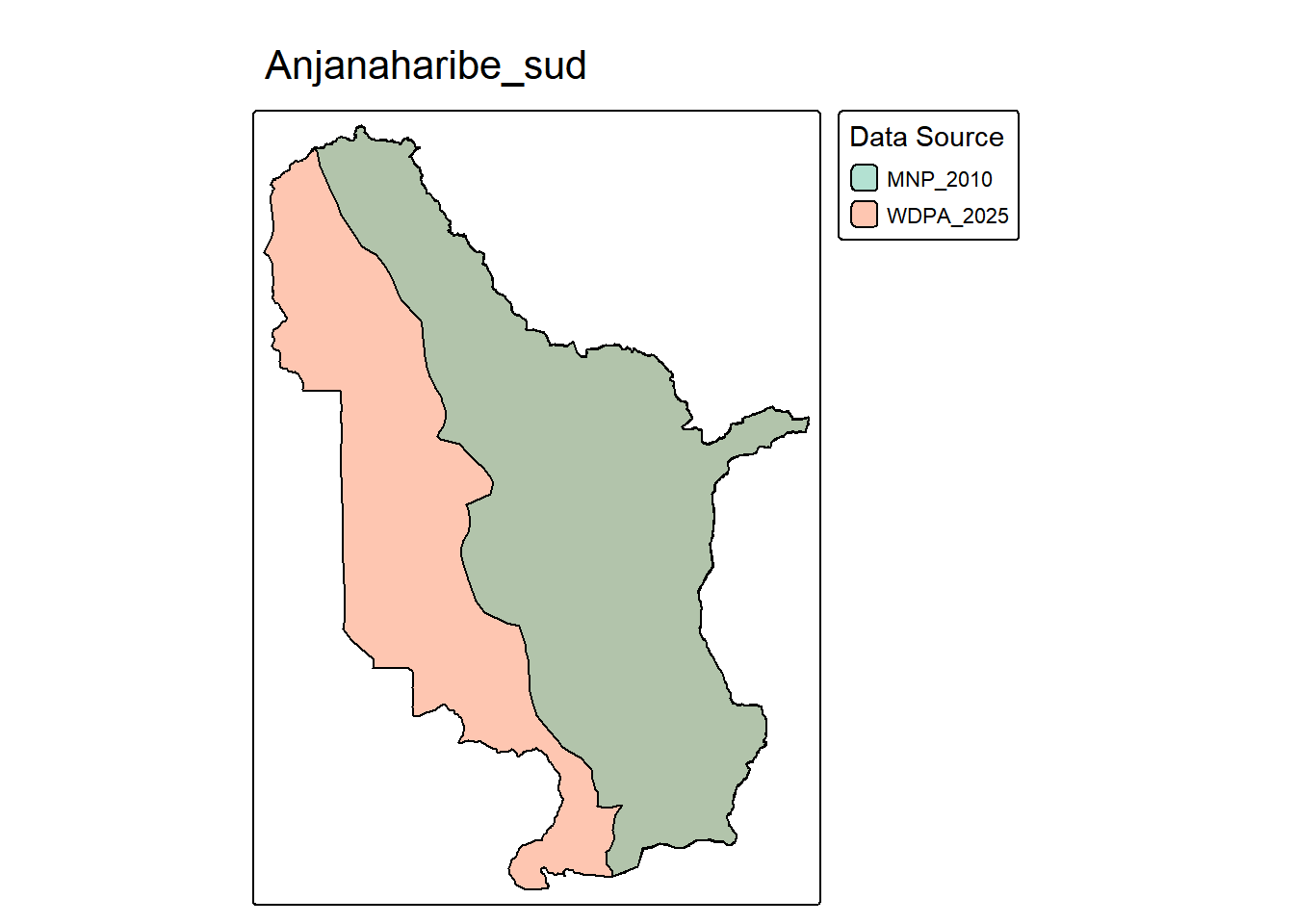
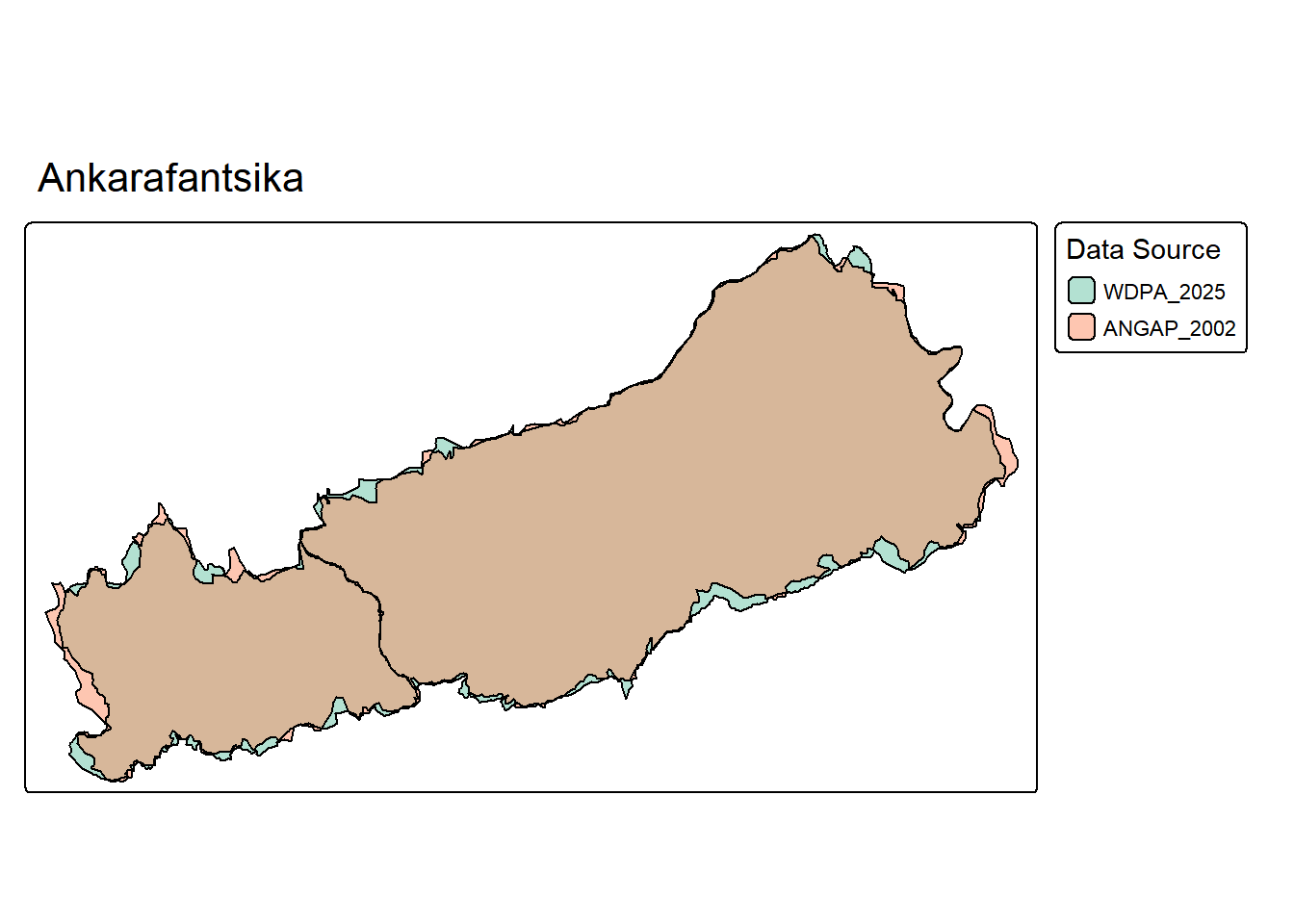
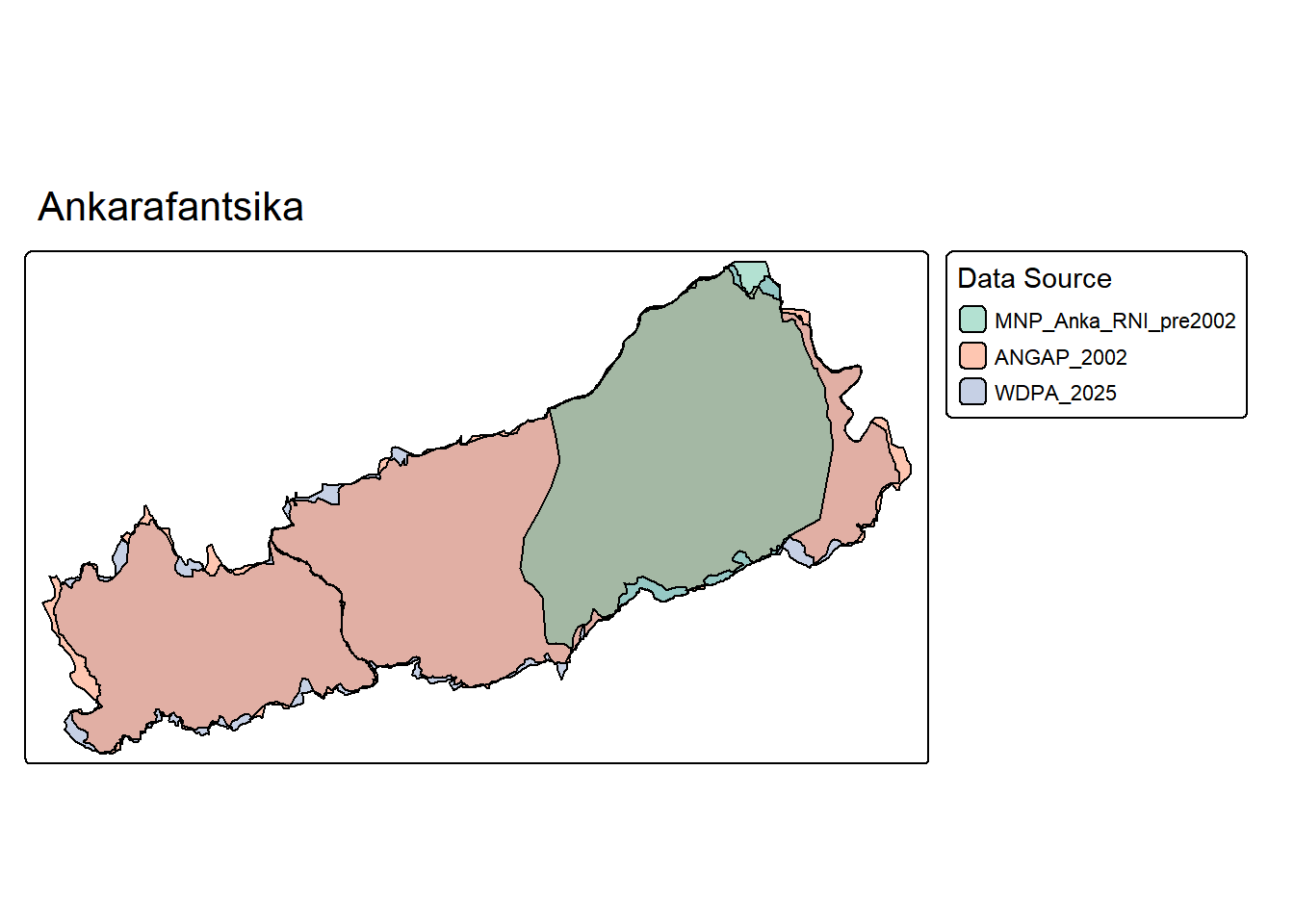
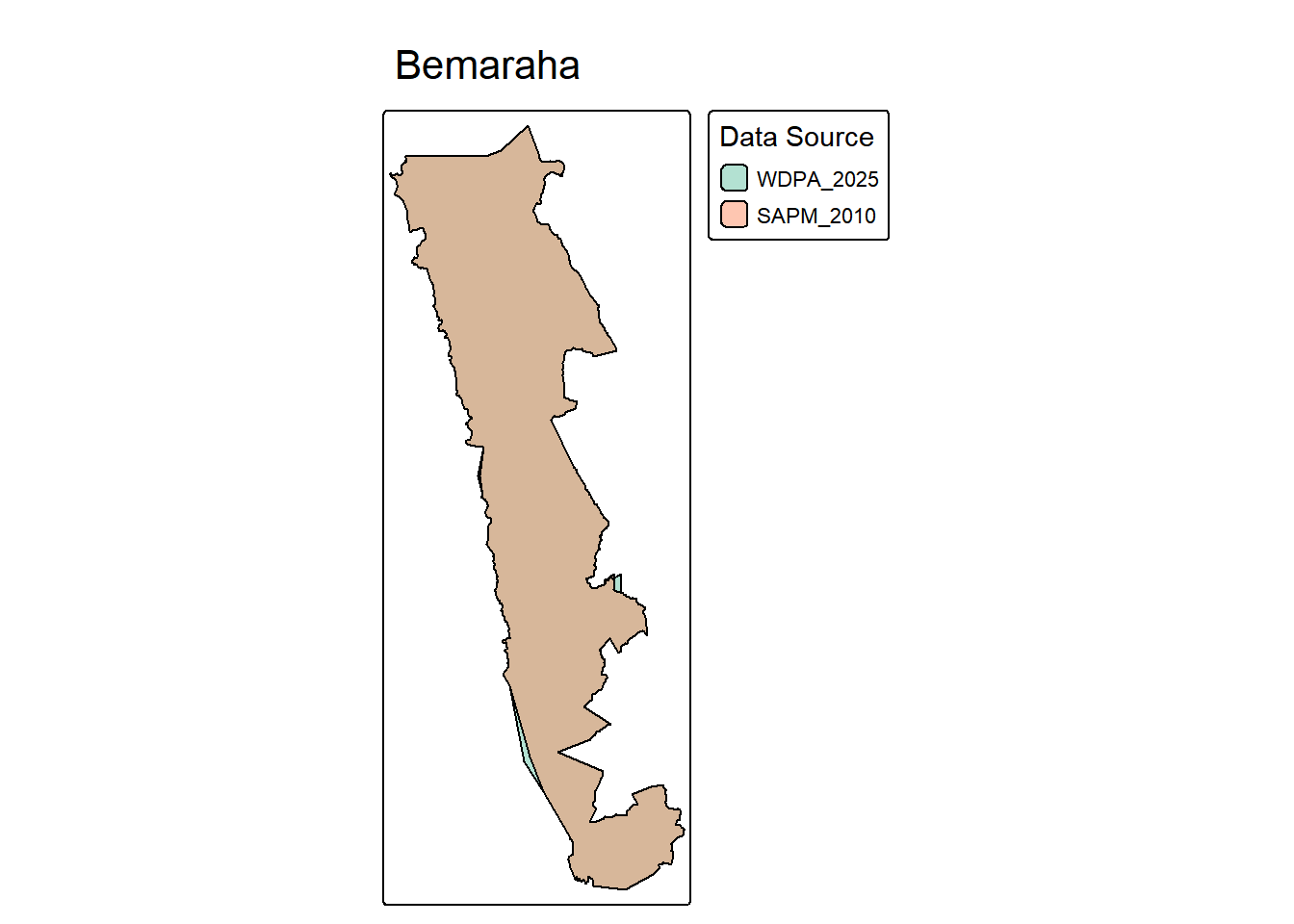
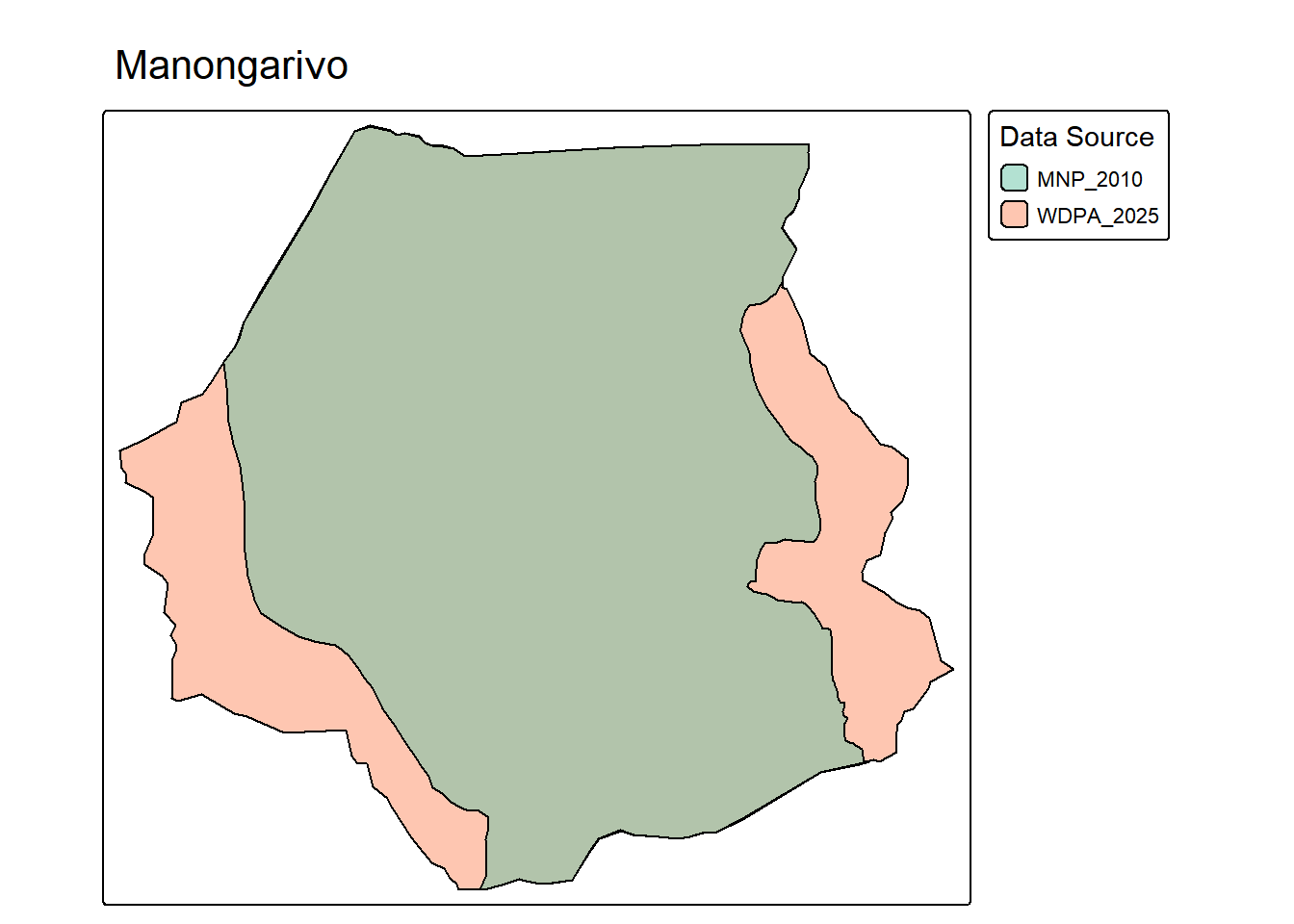
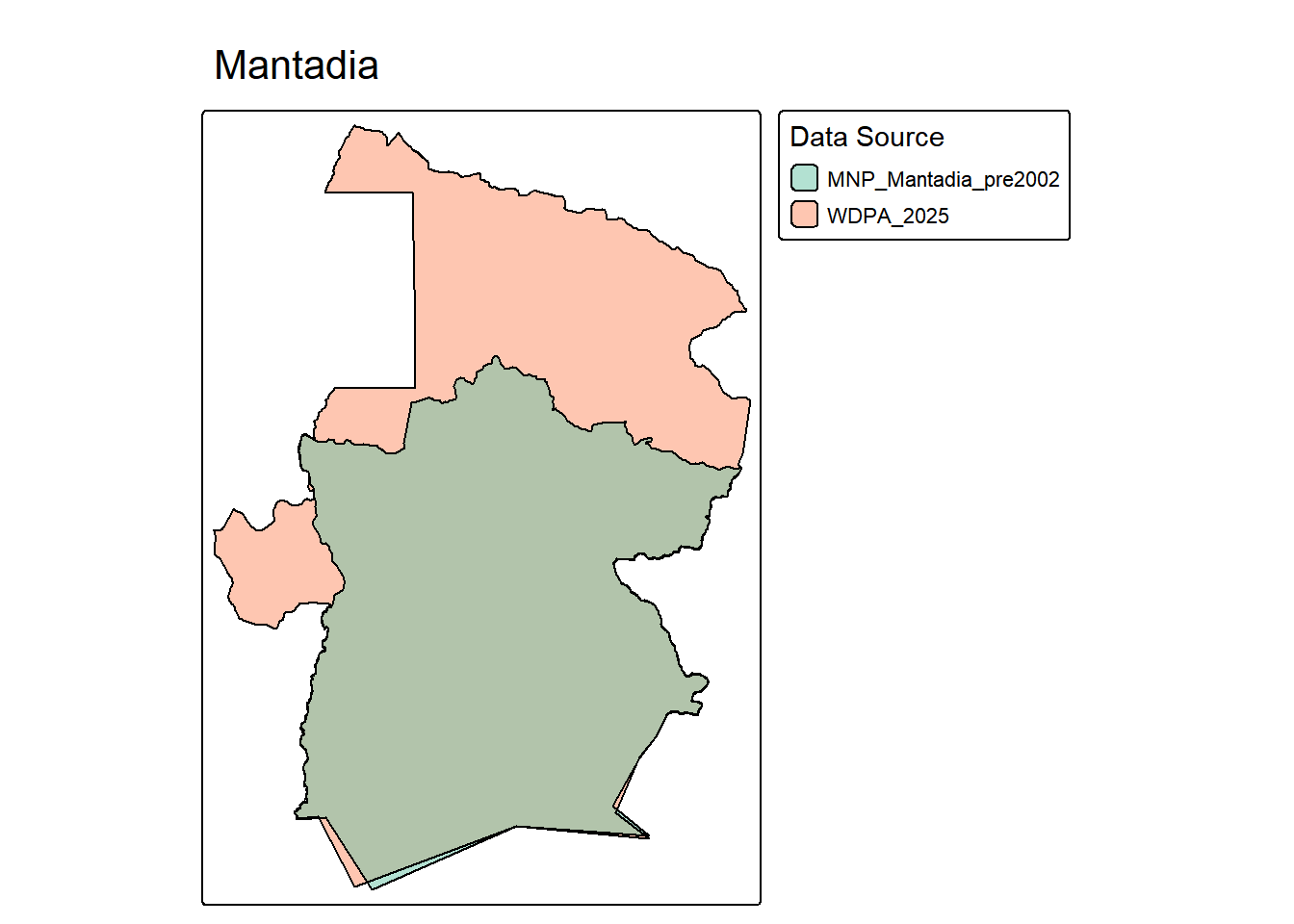
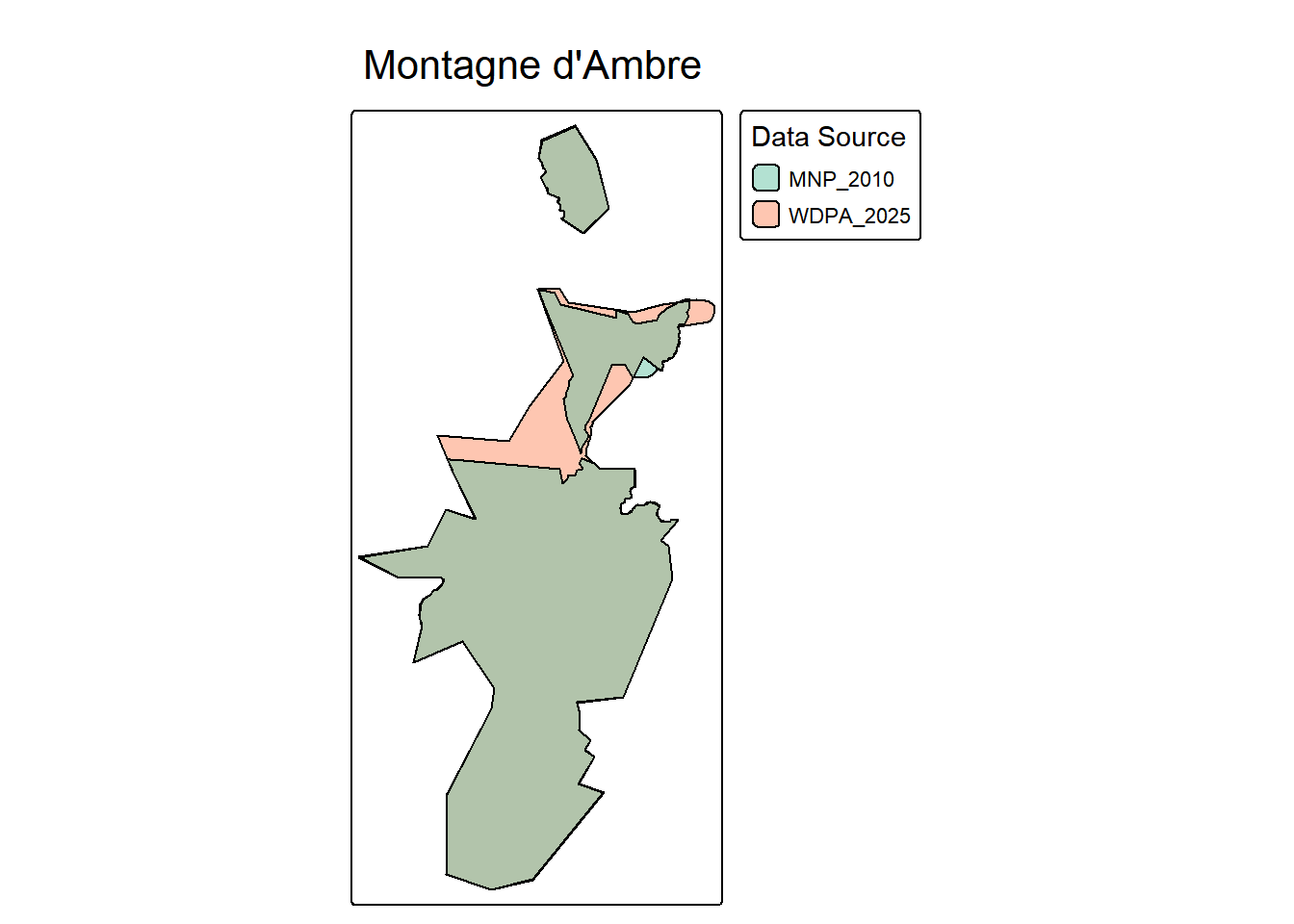
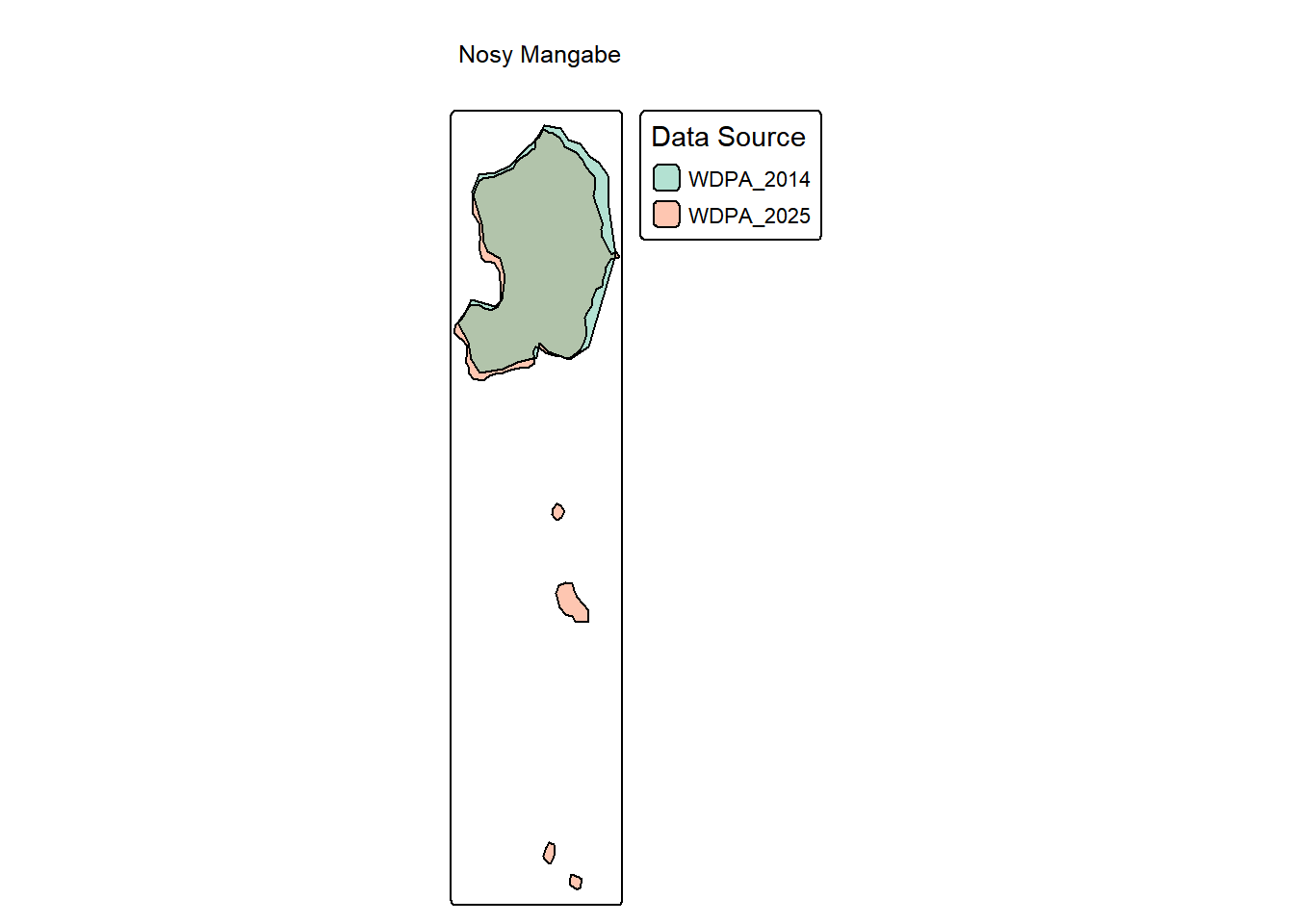
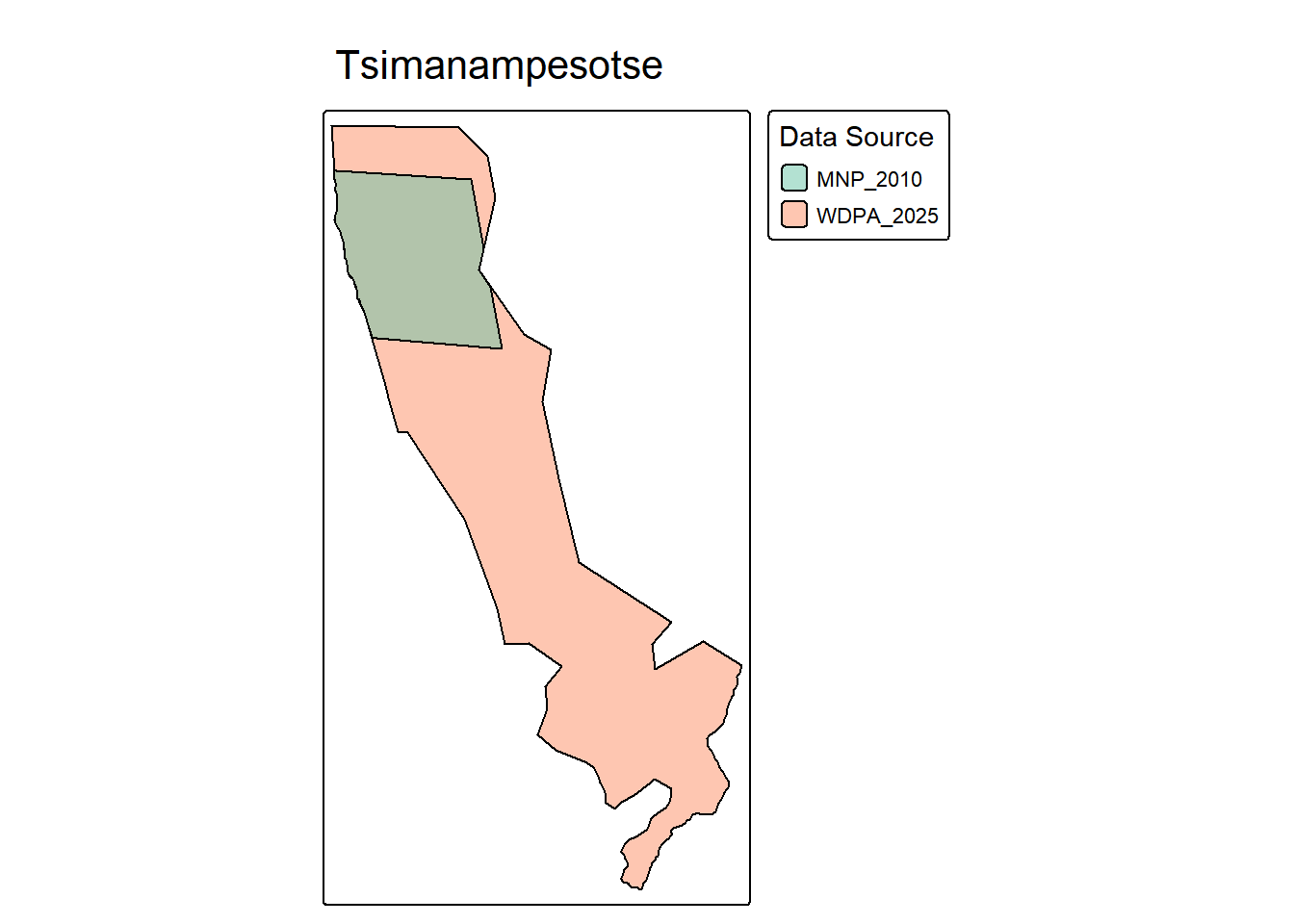
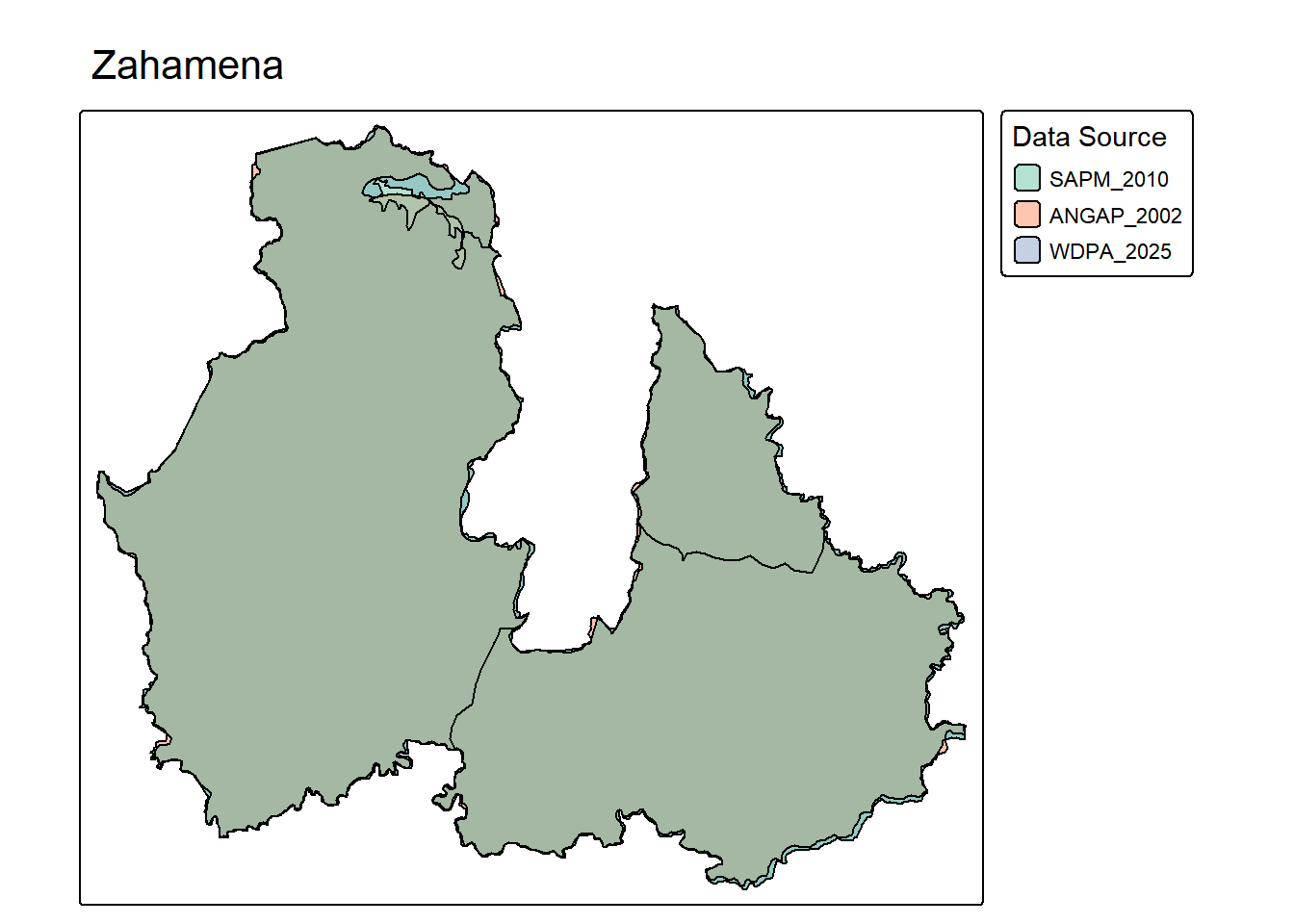
tmap_mode("plot")
all_PAs_conso <- read_rds("data/id/all_PAs_conso.rds")
resolve_wdpaid <- function(wdpa_name_or_id, decisions) {
# English: accept WDPAID (numeric) or WDPA_NAME (character) and return a single WDPAID
if (is.numeric(wdpa_name_or_id)) {
return(wdpa_name_or_id[1])
}
wdpaid <- decisions |>
filter(WDPA_NAME == wdpa_name_or_id) |>
pull(WDPAID) |>
first()
if (is.na(wdpaid)) {
stop("WDPAID introuvable pour: ", wdpa_name_or_id)
}
wdpaid
}
show_cnlegis_for_pa <- function(
wdpa_name_or_id,
decisions,
pattern = NULL,
columns = c(
"date_texte",
"type_texte",
"num_texte",
"type_decision",
"id_texte",
"objet_texte"
)
) {
# English: show all CNLEGIS decisions for a PA, optionally filter by a pattern on type_decision
# Returns a gt table with specified columns
require(gt)
wdpaid <- resolve_wdpaid(wdpa_name_or_id, decisions)
# Get PA name for title
wdpa_name <- if (is.numeric(wdpa_name_or_id)) {
decisions |>
filter(WDPAID == wdpaid) |>
pull(WDPA_NAME) |>
first()
} else {
wdpa_name_or_id
}
out <- decisions |>
filter(WDPAID == wdpaid) |>
arrange(date_texte)
if (!is.null(pattern)) {
out <- out |> filter(str_detect(type_decision, pattern))
}
# Select requested columns (only those that exist)
available_cols <- intersect(columns, names(out))
out <- out |> select(all_of(available_cols))
# Return as gt table with title
out |>
gt() |>
tab_header(
title = paste0("Entrées pour l'AP ", wdpa_name, " dans la base CNLEGIS")
)
}
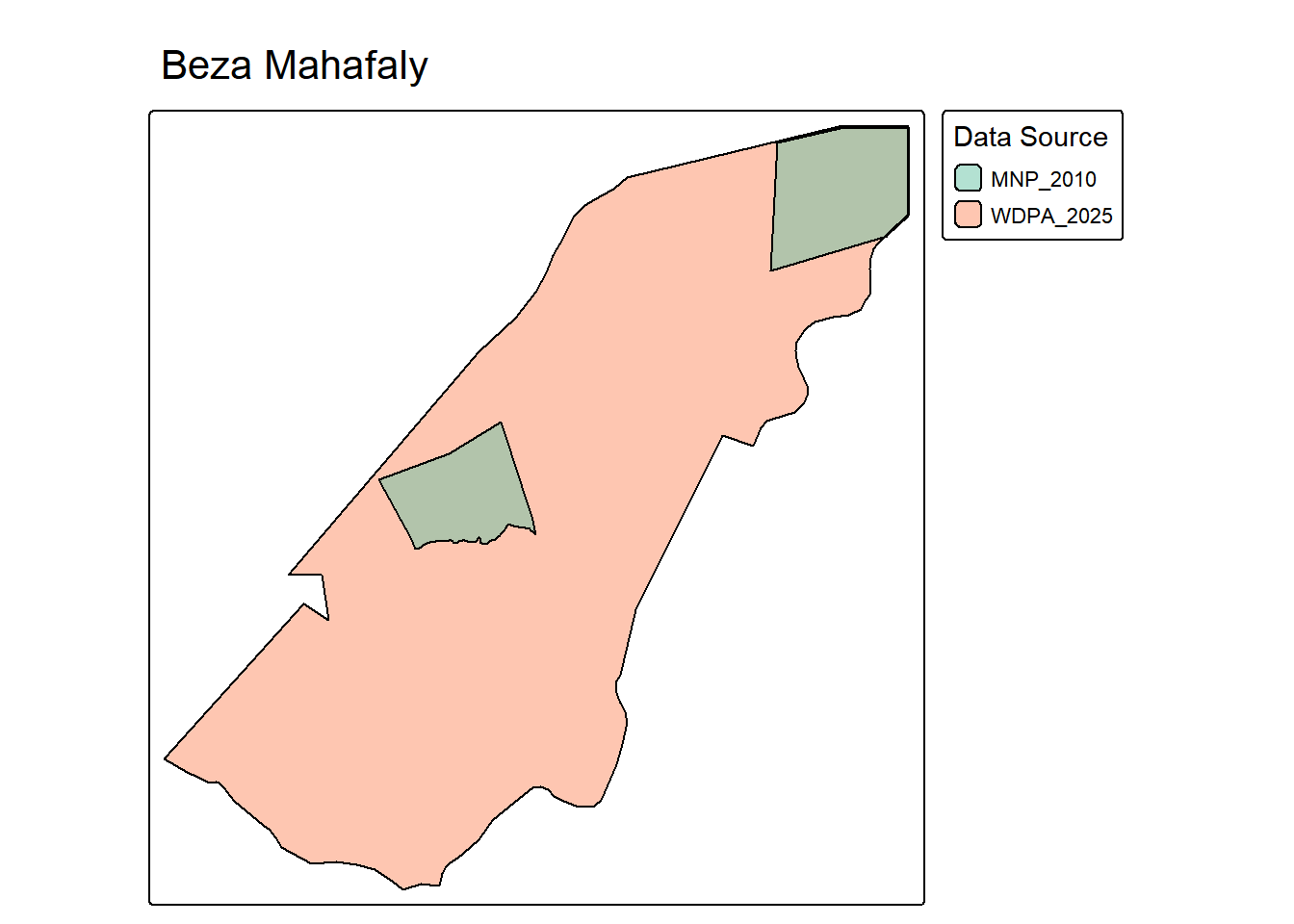
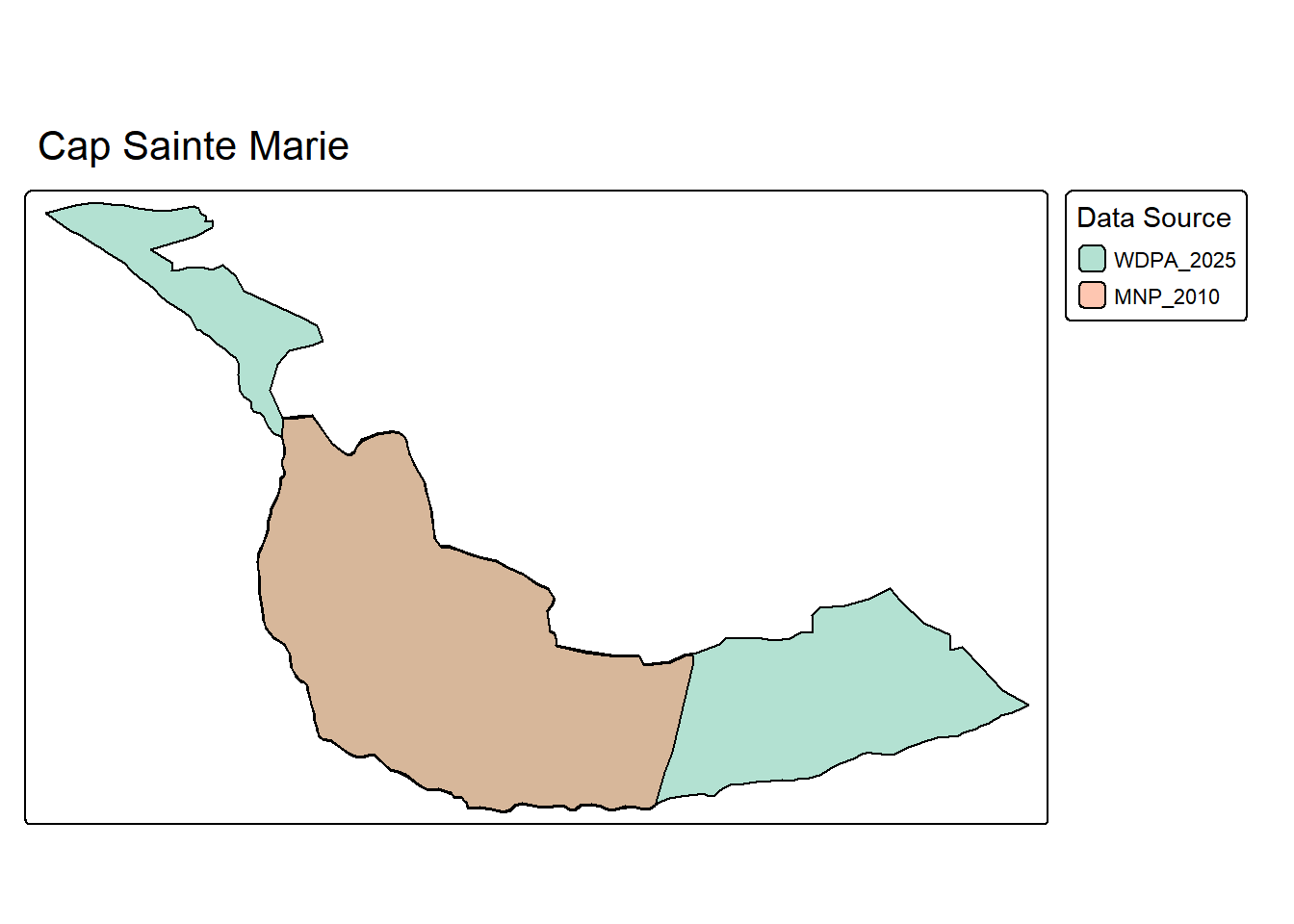
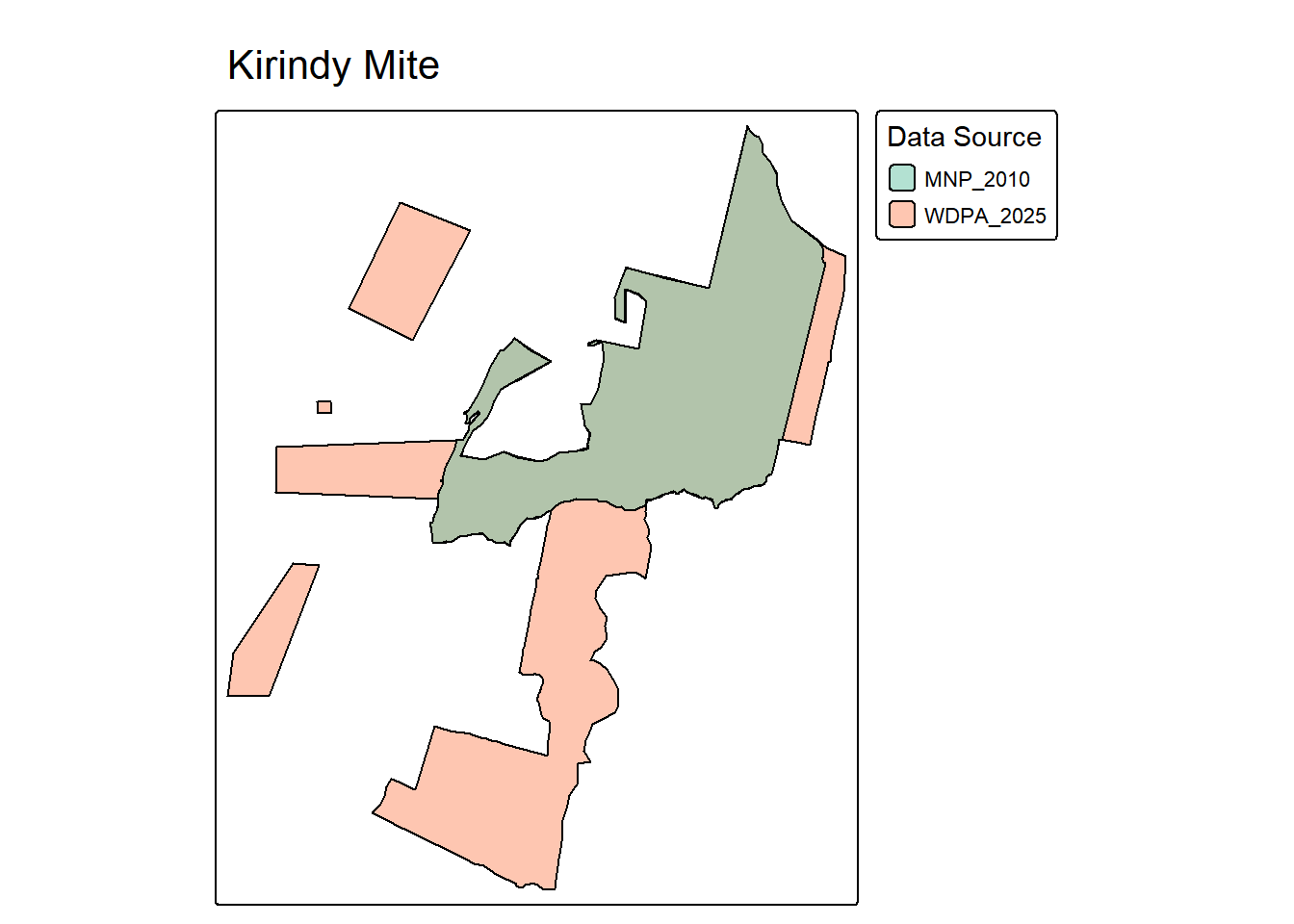
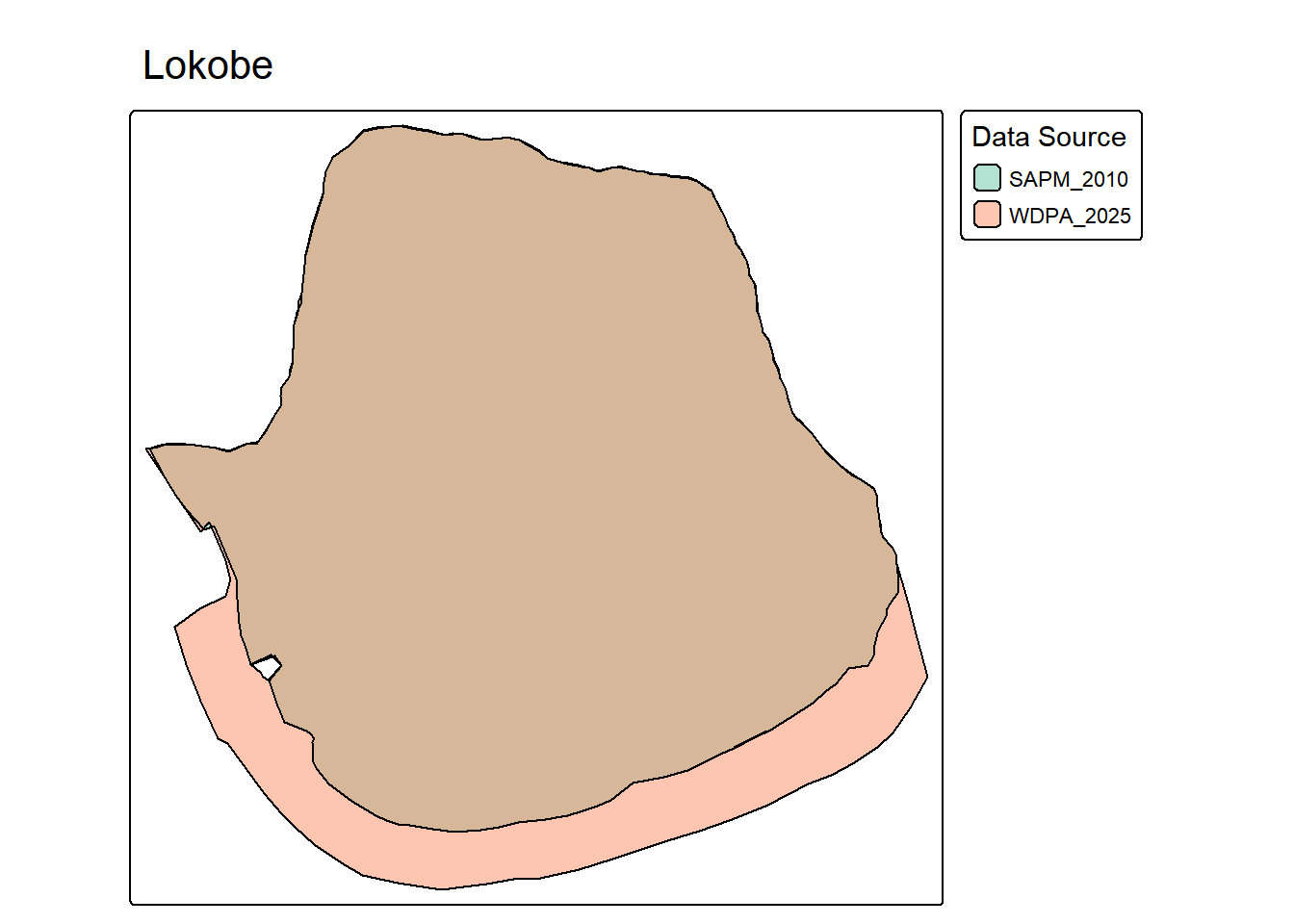
plot_pa_sources <- function(
wdpa_name,
data = all_PAs_conso,
decisions = pa_decisions,
wdpa_historical_path = "data/MDG_WDPA_Consolidated.parquet",
sources = NULL
) {
# Check if input is a WDPAID (integer) or name (string)
if (is.numeric(wdpa_name)) {
wdpaid <- wdpa_name
} else {
# Look up the WDPAID from pa_decisions
wdpaid <- decisions |>
filter(WDPA_NAME == wdpa_name) |>
pull(WDPAID) |>
first()
# Check if WDPAID was found
if (is.na(wdpaid)) {
message("No WDPAID found in pa_decisions for: ", wdpa_name)
return(NULL)
}
}
# Filter all observations matching this WDPAID from all_PAs_conso
pa_subset <- data |>
filter(WDPAID == wdpaid)
# Load and filter WDPA historical data
wdpa_historical <- read_parquet(wdpa_historical_path) |>
mutate(geometry = st_as_sfc(geometry)) |>
st_as_sf() |>
filter(WDPAID == wdpaid) |>
mutate(dataset_id = paste0("WDPA_", data_year)) |>
st_transform(st_crs(pa_subset))
# Combine both datasets
pa_subset <- bind_rows(pa_subset, wdpa_historical)
# Filter by specified sources if provided
if (!is.null(sources) && length(sources) > 0) {
pa_subset <- pa_subset |>
filter(dataset_id %in% sources) |>
# Convert to factor with levels in the order specified by sources
mutate(dataset_id = factor(dataset_id, levels = sources))
}
# Check if any results found
if (nrow(pa_subset) == 0) {
message("No protected area found with WDPAID: ", wdpaid)
return(NULL)
}
# Get summary information
n_obs <- nrow(pa_subset)
datasets <- unique(pa_subset$dataset_id)
# Create static plot map with all geometries in one layer (tmap v4 syntax)
tmap_mode("plot")
map <- tm_shape(pa_subset) +
tm_polygons(
fill = "dataset_id",
fill_alpha = 0.5,
col = "black",
lwd = 1,
fill.scale = tm_scale(values = "brewer.set2"),
fill.legend = tm_legend(
title = "Data Source",
position = tm_pos_out("right")
)
) +
tm_title(wdpa_name)
return(map)
}
# Add a spatial amendment to SAT based on a legal decision
#
# This function creates a SAT entry documenting a historical boundary or
# secondary zone that differs from the current WDPA representation. It links
# a geometry from curated spatial sources to a legal decision that marks
# when this geometry ceased to be valid.
#
# Working table format for efficient curation. Use export_amendments_to_yaml()
# to convert to standardized YAML schema.
#
# Parameters:
# sat: Existing SAT table (sf object) or NULL to initialize
# data: Consolidated spatial dataset (e.g., all_PAs_conso) containing
# multiple representations of PAs from different sources
# decisions: Legal decisions table with WDPAID linkage (e.g., pa_decisions)
# wdpa_name_or_id: Either WDPAID (numeric) or WDPA_NAME (character)
# decision_filter: Named list to identify the legal decision, can include:
# - year: numeric year of decision
# - type_decision_pattern: regex pattern for type_decision
# - num_texte: exact legal instrument number
# - id_texte: exact decision ID
# manual_decision: Optional named list for decisions not in CNLEGIS
# source_dataset_id: The dataset_id in 'data' containing the historical geometry
# amendment_type: Type of spatial amendment. Allowed values:
# - "boundary_modification": Legal change to external boundaries
# - "secondary_zoning": Additional zoning (core zones, buffers)
# - "correction": Data correction (wrong geometry in WDPA)
# valid_from: Optional start date (Date or character). If NULL, remains NA
# notes: Optional notes (defaults to decision object text)
#
# Returns:
# Updated SAT table (sf object) with new amendment(s) appended
add_modif_sat <- function(
sat,
data,
decisions,
wdpa_name_or_id,
decision_filter = NULL,
manual_decision = NULL,
source_dataset_id,
amendment_type = "boundary_modification",
valid_from = NULL,
notes = NULL
) {
# Helper: accept WDPAID (numeric) or WDPA_NAME (character) and return a single WDPAID
resolve_wdpaid <- function(wdpa_name_or_id, decisions) {
if (is.numeric(wdpa_name_or_id)) {
return(wdpa_name_or_id[1])
}
wdpaid <- decisions |>
filter(WDPA_NAME == wdpa_name_or_id) |>
pull(WDPAID) |>
first()
if (is.na(wdpaid)) {
stop("WDPAID introuvable pour: ", wdpa_name_or_id)
}
wdpaid
}
# Validate amendment_type for SAT
allowed_types_sat <- c(
"boundary_modification",
"secondary_zoning",
"correction"
)
if (!amendment_type %in% allowed_types_sat) {
stop(
"amendment_type must be one of: ",
paste(allowed_types_sat, collapse = ", "),
". Got: ",
amendment_type
)
}
wdpaid <- resolve_wdpaid(wdpa_name_or_id, decisions)
# Warn when boundary_modification lacks valid_from: without it,
# generate_timeline() cannot create the pre-modification temporal state.
if (amendment_type == "boundary_modification" && is.null(valid_from)) {
warning(
"add_modif_sat(): boundary_modification for WDPAID=", wdpaid,
" has no valid_from. The pre-modification period will not be ",
"represented in the timeline unless STATUS_YR provides a fallback."
)
}
# Use manual_decision if provided, otherwise search CNLEGIS database
if (!is.null(manual_decision)) {
# Manual decision provided - use it directly
dec <- tibble(
date_texte = manual_decision$date_texte,
type_texte = manual_decision$type_texte,
num_texte = manual_decision$num_texte,
id_texte = if (!is.null(manual_decision$id_texte)) {
manual_decision$id_texte
} else {
NA_character_
},
objet_texte = manual_decision$objet_texte,
cnlegis_url = NA_character_
)
} else {
# Search CNLEGIS database with filters
if (!is.list(decision_filter)) {
stop(
"decision_filter doit être une liste ou NULL si manual_decision est fourni."
)
}
# Select exactly one legal decision based on filters
dec <- decisions |>
filter(WDPAID == wdpaid)
if (!is.null(decision_filter$year)) {
dec <- dec |> filter(lubridate::year(date_texte) == decision_filter$year)
}
if (!is.null(decision_filter$type_decision_pattern)) {
dec <- dec |>
filter(str_detect(type_decision, decision_filter$type_decision_pattern))
}
if (!is.null(decision_filter$num_texte)) {
dec <- dec |> filter(num_texte == decision_filter$num_texte)
}
if (!is.null(decision_filter$id_texte)) {
dec <- dec |> filter(id_texte == decision_filter$id_texte)
}
dec <- dec |> arrange(date_texte)
if (nrow(dec) == 0) {
stop(
"Aucune décision CNLEGIS ne correspond au filtre pour WDPAID=",
wdpaid
)
}
if (nrow(dec) > 1) {
stop(
"Filtre CNLEGIS ambigu: plusieurs décisions correspondent. Raffiner decision_filter."
)
}
}
# Extract historical geometry from consolidated spatial data
geom_before <- data |>
filter(WDPAID == wdpaid, dataset_id == source_dataset_id) |>
filter(dataset_id != "CNLEGIS_2024") |>
st_zm(drop = TRUE, what = "ZM") |>
st_make_valid()
if (nrow(geom_before) == 0) {
stop(
"Aucune géométrie trouvée pour source_dataset_id=",
source_dataset_id,
" et WDPAID=",
wdpaid
)
}
# Build SAT entry with geometry and metadata
sat_entry <- geom_before |>
mutate(
WDPAID = wdpaid,
amendment_type = amendment_type,
valid_from = if (!is.null(valid_from)) {
as.Date(valid_from)
} else {
as.Date(NA)
},
valid_to = dec$date_texte[1],
date_precision = "day",
data_source = source_dataset_id,
legal_source = dec$num_texte[1],
cnlegis_url = if ("cnlegis_url" %in% names(dec)) {
dec$cnlegis_url[1]
} else {
NA_character_
},
notes = ifelse(is.null(notes), dec$objet_texte[1], notes)
) |>
select(
WDPAID,
geometry,
amendment_type,
valid_from,
valid_to,
date_precision,
data_source,
legal_source,
cnlegis_url,
notes
)
# Initialize or append to SAT
if (is.null(sat)) {
sat_new <- sat_entry
} else {
sat_new <- bind_rows(sat, sat_entry)
}
# Assign stable sequential amendment_id
sat_new <- sat_new |>
mutate(amendment_id = row_number()) |>
relocate(amendment_id, .before = WDPAID)
sat_new
}
# Export amendments to YAML format for dynamic_wdpa registry
#
# This function converts working tables (sat/fat) to standardized YAML files
# following the dynamic_wdpa amendment schema. Spatial amendments include
# separate GeoJSON geometry files.
#
# Parameters:
# spatial: SAT table (sf object) with spatial amendments, or NULL
# attribute: FAT table (tibble) with attribute amendments, or NULL
# output_dir: Directory for YAML files (default: "data/amendments")
# iso3: ISO3 country code (default: "MDG")
# wdpa_reference: WDPA dataset for PA name lookup (default: wdpa_mdg)
#
# Output structure:
# {output_dir}/{iso3}-{wdpaid}-{year}-{type}-{seq}.yml
# {output_dir}/geoms/{iso3}-{wdpaid}-{year}-{type}-{seq}.geojson
#
# Returns: tibble with amendment_id and file paths
export_amendments_to_yaml <- function(
spatial = NULL,
attribute = NULL,
output_dir = "data/amendments",
iso3 = "MDG",
wdpa_reference = wdpa_mdg
) {
require(yaml)
require(sf)
require(dplyr)
require(stringr)
# Create output directories
dir.create(output_dir, showWarnings = FALSE, recursive = TRUE)
geom_dir <- file.path(output_dir, "geoms")
dir.create(geom_dir, showWarnings = FALSE, recursive = TRUE)
# Helper: get PA name from WDPAID
get_wdpa_name <- function(wdpaid, wdpa_ref) {
name <- wdpa_ref |>
st_drop_geometry() |>
filter(WDPAID == wdpaid) |>
pull(NAME) |>
first()
if (is.na(name)) {
return(as.character(wdpaid))
}
name
}
# Helper: generate amendment_id
generate_amendment_id <- function(
iso3,
wdpaid,
valid_from,
valid_to,
amendment_type,
seq
) {
year <- if (
amendment_type == "temporary_protection" && !is.na(valid_from)
) {
lubridate::year(valid_from)
} else if (!is.na(valid_to)) {
lubridate::year(valid_to)
} else {
"NODATE"
}
sprintf("%s-%d-%s-%s-%03d", iso3, wdpaid, year, amendment_type, seq)
}
# Helper: create legal_instrument object
create_legal_instrument <- function(row) {
# Check if we have legal instrument data (check column existence first)
has_fat_cols <- "legal_instrument_number" %in% names(row)
has_sat_cols <- "legal_source" %in% names(row)
if (!has_fat_cols && !has_sat_cols) {
return(NULL)
}
# If we have neither SAT nor FAT data populated, return NULL
if (
has_fat_cols &&
is.na(row$legal_instrument_number) &&
has_sat_cols &&
is.na(row$legal_source)
) {
return(NULL)
}
if (!has_fat_cols && has_sat_cols && is.na(row$legal_source)) {
return(NULL)
}
# Determine source and structure
if (
has_fat_cols &&
!is.null(row$legal_instrument_source) &&
!is.na(row$legal_instrument_source)
) {
# FAT format
list(
source = row$legal_instrument_source,
type = row$legal_instrument_type,
number = row$legal_instrument_number,
date = as.character(row$legal_instrument_date),
id = if (!is.na(row$legal_instrument_id)) {
row$legal_instrument_id
} else {
NULL
},
url = if (!is.na(row$legal_instrument_url)) {
row$legal_instrument_url
} else {
NULL
}
)
} else {
# SAT format (simpler)
list(
source = "CNLEGIS",
type = "décret", # assume decree if not specified
number = row$legal_source,
date = NULL, # not available in SAT
id = NULL,
url = if (!is.na(row$cnlegis_url)) row$cnlegis_url else NULL
)
}
}
# Helper: generate a human-readable temporal description from amendment fields
generate_temporal_description <- function(
amendment_type,
valid_from,
valid_to,
legal_instrument
) {
type_labels <- c(
boundary_modification = "Modification des limites",
secondary_zoning = "Zonage secondaire",
correction = "Correction de donnees",
status_change = "Changement de statut",
temporary_protection = "Protection temporaire",
governance_change = "Changement de gouvernance"
)
label <- type_labels[amendment_type] %||% amendment_type
parts <- label
if (!is.null(valid_from) && !is.null(valid_to)) {
parts <- paste0(parts, " du ", valid_from, " au ", valid_to)
} else if (!is.null(valid_from)) {
parts <- paste0(parts, " depuis le ", valid_from)
} else if (!is.null(valid_to)) {
parts <- paste0(parts, " jusqu'au ", valid_to)
}
if (!is.null(legal_instrument) && !is.null(legal_instrument$number)) {
instr_type <- legal_instrument$type %||% "texte"
# Avoid stutter when instrument type matches the amendment label
if (tolower(instr_type) == tolower(label)) {
parts <- paste0(parts, " (n. ", legal_instrument$number, ")")
} else {
parts <- paste0(parts, " selon ", instr_type, " n. ", legal_instrument$number)
}
if (!is.null(legal_instrument$date)) {
parts <- paste0(parts, " du ", legal_instrument$date)
}
}
paste0(parts, ".")
}
exported <- list()
# Process spatial amendments
if (!is.null(spatial) && nrow(spatial) > 0) {
spatial_grouped <- spatial |>
group_by(WDPAID, valid_to, amendment_type) |>
mutate(seq = row_number()) |>
ungroup()
for (i in seq_len(nrow(spatial_grouped))) {
row <- spatial_grouped[i, ]
amendment_id <- generate_amendment_id(
iso3,
row$WDPAID,
row$valid_from,
row$valid_to,
row$amendment_type,
row$seq
)
# Save geometry to GeoJSON
geom_filename <- paste0(amendment_id, ".geojson")
geom_path <- file.path(geom_dir, geom_filename)
geom_relative <- file.path("geoms", geom_filename)
row |>
select(geometry) |>
st_transform(4326) |>
st_write(geom_path, delete_dsn = TRUE, quiet = TRUE)
# Build YAML structure
amendment <- list(
amendment_id = amendment_id,
iso3 = iso3,
wdpaid = as.integer(row$WDPAID),
wdpa_name = get_wdpa_name(row$WDPAID, wdpa_reference),
amendment_kind = "spatial",
amendment_type = row$amendment_type,
valid_from = if (!is.na(row$valid_from)) {
as.character(row$valid_from)
} else {
NULL
},
valid_to = if (!is.na(row$valid_to)) {
as.character(row$valid_to)
} else {
NULL
},
legal_instrument = create_legal_instrument(row),
temporal_description = generate_temporal_description(
row$amendment_type,
if (!is.na(row$valid_from)) as.character(row$valid_from) else NULL,
if (!is.na(row$valid_to)) as.character(row$valid_to) else NULL,
create_legal_instrument(row)
),
notes = if (!is.na(row$notes)) row$notes else NULL,
geometry_ref = geom_relative,
geometry_crs_epsg = 4326L,
geometry_source_dataset_id = row$data_source
)
# Remove NULL values
amendment <- amendment[!sapply(amendment, is.null)]
# Write YAML
yaml_filename <- paste0(amendment_id, ".yml")
yaml_path <- file.path(output_dir, yaml_filename)
write_yaml(amendment, yaml_path)
exported[[length(exported) + 1]] <- list(
amendment_id = amendment_id,
kind = "spatial",
yaml_path = yaml_path,
geom_path = geom_path
)
}
}
# Process attribute amendments
if (!is.null(attribute) && nrow(attribute) > 0) {
attribute_grouped <- attribute |>
group_by(WDPAID, valid_to, amendment_type) |>
mutate(seq = row_number()) |>
ungroup()
for (i in seq_len(nrow(attribute_grouped))) {
row <- attribute_grouped[i, ]
amendment_id <- generate_amendment_id(
iso3,
row$WDPAID,
row$valid_from,
row$valid_to,
row$amendment_type,
row$seq
)
# Extract non-NA WDPA attributes
wdpa_attributes <- c(
"WDPA_PID",
"PA_DEF",
"NAME",
"ORIG_NAME",
"DESIG",
"DESIG_ENG",
"DESIG_TYPE",
"IUCN_CAT",
"INT_CRIT",
"MARINE",
"REP_M_AREA",
"REP_AREA",
"NO_TAKE",
"NO_TK_AREA",
"STATUS",
"STATUS_YR",
"GOV_TYPE",
"OWN_TYPE",
"MANG_AUTH",
"MANG_PLAN",
"VERIF",
"METADATAID",
"SUB_LOC",
"PARENT_ISO3",
"ISO3",
"SUPP_INFO",
"CONS_OBJ"
)
attributes_list <- list()
for (attr in wdpa_attributes) {
if (attr %in% names(row) && !is.na(row[[attr]])) {
attributes_list[[attr]] <- row[[attr]]
}
}
# Build YAML structure
amendment <- list(
amendment_id = amendment_id,
iso3 = iso3,
wdpaid = as.integer(row$WDPAID),
wdpa_name = get_wdpa_name(row$WDPAID, wdpa_reference),
amendment_kind = "attribute",
amendment_type = row$amendment_type,
valid_from = if (!is.na(row$valid_from)) {
as.character(row$valid_from)
} else {
NULL
},
valid_to = if (!is.na(row$valid_to)) {
as.character(row$valid_to)
} else {
NULL
},
legal_instrument = create_legal_instrument(row),
temporal_description = generate_temporal_description(
row$amendment_type,
if (!is.na(row$valid_from)) as.character(row$valid_from) else NULL,
if (!is.na(row$valid_to)) as.character(row$valid_to) else NULL,
create_legal_instrument(row)
),
notes = if (!is.na(row$notes)) row$notes else NULL,
attributes = if (length(attributes_list) > 0) attributes_list else NULL
)
# Remove NULL values
amendment <- amendment[!sapply(amendment, is.null)]
# Write YAML
yaml_filename <- paste0(amendment_id, ".yml")
yaml_path <- file.path(output_dir, yaml_filename)
write_yaml(amendment, yaml_path)
exported[[length(exported) + 1]] <- list(
amendment_id = amendment_id,
kind = "attribute",
yaml_path = yaml_path,
geom_path = NA_character_
)
}
}
# Return summary
bind_rows(exported)
}
# Add attribute amendments to FAT based on a legal decision
#
# This function creates FAT entries documenting historical attribute states
# that differ from current WDPA representation. It uses a wide format where
# each amendment is a single row with one column per WDPA attribute that may
# have changed.
#
# Working table format for efficient curation. Use export_amendments_to_yaml()
# to convert to standardized YAML schema.
#
# Parameters:
# fat: Existing FAT table (tibble) or NULL to initialize
# decisions: Legal decisions table with WDPAID linkage (e.g., pa_decisions)
# wdpa_name_or_id: Either WDPAID (numeric) or WDPA_NAME (character)
# decision_filter: Named list to identify the legal decision (optional if using manual_decision)
# manual_decision: Optional named list for decisions not in CNLEGIS
# attributes: Named list of attribute changes, e.g.:
# list(DESIG = "Réserve Naturelle Intégrale", IUCN_CAT = "Ia")
# Only attributes that differ from WDPA should be provided.
# amendment_type: Type of attribute amendment. Allowed values:
# - "status_change": Change in designation type (RNI to PN, etc.)
# - "temporary_protection": legally binding but bounded in time (e.g., arrêté de protection provisoire)
# - "governance_change": Change in management authority
# - "correction": Data correction (wrong attribute in WDPA)
# valid_from: Optional start date (Date or character). If NULL, remains NA
# notes: Optional notes (defaults to decision object text)
#
# Returns:
# Updated FAT table (tibble) with new amendment row appended. Unspecified
# WDPA attributes are set to NA (will inherit from WDPA in CAR).
add_modif_fat <- function(
fat,
decisions,
wdpa_name_or_id,
decision_filter = NULL,
manual_decision = NULL,
attributes,
amendment_type = "status_change",
valid_from = NULL,
valid_to = NULL,
notes = NULL
) {
resolve_wdpaid <- function(wdpa_name_or_id, decisions) {
if (is.numeric(wdpa_name_or_id)) {
return(wdpa_name_or_id[1])
}
wdpaid <- decisions |>
filter(WDPA_NAME == wdpa_name_or_id) |>
pull(WDPAID) |>
first()
if (is.na(wdpaid)) {
stop("WDPAID introuvable pour: ", wdpa_name_or_id)
}
wdpaid
}
# Validate that either decision_filter or manual_decision is provided
if (is.null(decision_filter) && is.null(manual_decision)) {
stop("Either decision_filter or manual_decision must be provided.")
}
if (!is.null(decision_filter) && !is.null(manual_decision)) {
stop("Cannot use both decision_filter and manual_decision. Choose one.")
}
# Validate amendment_type for FAT
allowed_types_fat <- c(
"status_change",
"temporary_protection",
"governance_change",
"correction"
)
if (!amendment_type %in% allowed_types_fat) {
stop(
"amendment_type must be one of: ",
paste(allowed_types_fat, collapse = ", "),
". Got: ",
amendment_type
)
}
wdpaid <- resolve_wdpaid(wdpa_name_or_id, decisions)
# Handle manual decision (not in CNLEGIS)
if (!is.null(manual_decision)) {
if (!is.list(manual_decision)) {
stop("manual_decision must be a list.")
}
required_fields <- c("date_texte", "type_texte", "num_texte")
missing <- setdiff(required_fields, names(manual_decision))
if (length(missing) > 0) {
stop(
"manual_decision missing required fields: ",
paste(missing, collapse = ", ")
)
}
dec <- tibble(
date_texte = as.Date(manual_decision$date_texte),
type_texte = manual_decision$type_texte,
num_texte = manual_decision$num_texte,
id_texte = manual_decision$id_texte %||% NA_character_,
objet_texte = manual_decision$objet_texte %||% NA_character_
)
} else {
# Handle CNLEGIS decision
if (!is.list(decision_filter)) {
stop("decision_filter doit être une liste.")
}
# Select exactly one legal decision based on filters
dec <- decisions |>
filter(WDPAID == wdpaid)
if (!is.null(decision_filter$year)) {
dec <- dec |> filter(lubridate::year(date_texte) == decision_filter$year)
}
if (!is.null(decision_filter$type_decision_pattern)) {
dec <- dec |>
filter(str_detect(type_decision, decision_filter$type_decision_pattern))
}
if (!is.null(decision_filter$num_texte)) {
dec <- dec |> filter(num_texte == decision_filter$num_texte)
}
if (!is.null(decision_filter$id_texte)) {
dec <- dec |> filter(id_texte == decision_filter$id_texte)
}
dec <- dec |> arrange(date_texte)
if (nrow(dec) == 0) {
stop(
"Aucune décision CNLEGIS ne correspond au filtre pour WDPAID=",
wdpaid
)
}
if (nrow(dec) > 1) {
stop("Filtre CNLEGIS ambigu: plusieurs décisions correspondent.")
}
}
# Determine date precision
date_precision <- if (!is.na(dec$date_texte[1])) {
"day"
} else if (!is.na(lubridate::year(dec$date_texte[1]))) {
"year"
} else {
NA_character_
}
# Define all possible WDPA attributes (wide format columns)
wdpa_attributes <- c(
"WDPA_PID",
"PA_DEF",
"NAME",
"ORIG_NAME",
"DESIG",
"DESIG_ENG",
"DESIG_TYPE",
"IUCN_CAT",
"INT_CRIT",
"MARINE",
"REP_M_AREA",
"REP_AREA",
"NO_TAKE",
"NO_TK_AREA",
"STATUS",
"STATUS_YR",
"GOV_TYPE",
"OWN_TYPE",
"MANG_AUTH",
"MANG_PLAN",
"VERIF",
"METADATAID",
"SUB_LOC",
"PARENT_ISO3",
"ISO3",
"SUPP_INFO",
"CONS_OBJ"
)
# Determine legal instrument source
legal_source <- if (!is.null(manual_decision)) {
"manual"
} else {
"CNLEGIS"
}
# Create base FAT entry with metadata
fat_entry <- tibble(
WDPAID = wdpaid,
valid_from = if (!is.null(valid_from)) {
as.Date(valid_from)
} else {
as.Date(NA)
},
valid_to = if (!is.null(valid_to)) {
as.Date(valid_to)
} else {
as.Date(NA) # NULL valid_to stays NA (no end date)
},
date_precision = date_precision,
legal_instrument_type = tolower(dec$type_texte[1]),
legal_instrument_number = dec$num_texte[1],
legal_instrument_date = dec$date_texte[1],
legal_instrument_source = legal_source,
legal_instrument_id = if (!is.null(manual_decision)) {
dec$id_texte[1]
} else if ("cnlegis_url" %in% names(dec)) {
dec$id_texte[1]
} else {
NA_character_
},
legal_instrument_url = if (!is.null(manual_decision)) {
NA_character_
} else if ("cnlegis_url" %in% names(dec)) {
dec$cnlegis_url[1]
} else {
NA_character_
},
amendment_type = amendment_type,
notes = ifelse(
is.null(notes),
if (!is.na(dec$objet_texte[1])) dec$objet_texte[1] else NA_character_,
notes
)
)
# Add WDPA attribute columns (all NA initially)
for (attr in wdpa_attributes) {
fat_entry[[attr]] <- NA_character_
}
# Populate provided attributes
for (attr_name in names(attributes)) {
if (attr_name %in% wdpa_attributes) {
fat_entry[[attr_name]] <- as.character(attributes[[attr_name]])
} else {
warning(
"Attribute '",
attr_name,
"' is not a recognized WDPA field and will be ignored."
)
}
}
# Reorder columns: metadata first, then WDPA attributes
fat_entry <- fat_entry |>
select(
WDPAID,
valid_from,
valid_to,
date_precision,
all_of(wdpa_attributes),
legal_instrument_type,
legal_instrument_number,
legal_instrument_date,
legal_instrument_source,
legal_instrument_id,
legal_instrument_url,
amendment_type,
notes
)
# Initialize or append to FAT
if (is.null(fat)) {
fat_new <- fat_entry
} else {
fat_new <- bind_rows(fat, fat_entry)
}
# Assign stable sequential amendment_id
fat_new <- fat_new |>
mutate(amendment_id = row_number()) |>
relocate(amendment_id, .before = WDPAID)
fat_new
}