Le document illustre l’application de la méthode de matching dans l’analyse. L’objectif de cette méthode est d’équilibrer les échantillons, c’est-à-dire de maximiser la comparabilité entre les groupes de traitement et de contrôle en termes de caractéristiques observables (Ho et al. 2007). Nous comparons donc des groupes traités et contrôles en les appariant selon 5 covariables environnementales (taux de couvert forestier en 2000, la pente, l’altitude, la densité de population en 2000 et l’accessibilité en 2000).
En effet, si les deux groupes sont très différents avant le traitement, il est difficile de savoir si les différences observées après viennent du traitement ou simplement de ces différences initiales. D’où l’importance du matching, qui permet de neutraliser ces différences. Plus précisement, nous utilisons le genetic matching, une variante des méthodes de matching. Bien qu’ayant le même objectif, cette approche repose sur des algorithmes d’optimisation qui ajustent les facteurs de confusion susceptibles d’influencer à la fois la probabilité de recevoir le traitement et les résultats observés.
8.1 Méthodes
Nous réalisons le matching à l’aide de la méthode genetic matching, en utilisant la fonction GenMatch() du package R MatchIt. Cette méthode combine les variables de matching en une seule mesure unique de distance “Mahalanobis distance matching”. Cette distance mesurera la différence entre les unités des groupes appariés pour quantifier la similitude entre les deux groupes d’observations, tout en tenant compte des corrélations entre les covariables et de leurs covariances (Diamond and Sekhon 2013).
Dans un premier temps, nous appliquons la fonction GenMatch() pour identifier la combinaison optimale de poids attribués à chaque covariable, dans le but de maximiser l’équilibre entre le groupe de traitement et de contrôle. Nous obtenons une matrice de poids mais aucune paire n’est encore formée. Dans un second temps, nous utilisons la fonction matchIt(), en intégrant la pondération trouvée auparavant, afin de constituer les paires entre les unités traitées et non traitées.
8.2 Exécution du matching pour toutes les années
Code
# Library library(tidyverse) # Manipulation et visualisation des donnéeslibrary(sf) # Analyse des données spatialeslibrary(tmap) # Analyse cartographiquelibrary(MatchIt) # Matchinglibrary(ggplot2) # Figurelibrary(rbounds) # Analyse de sensibilitélibrary(rgenoud) # Implementation de l'algorithme génétiquelibrary(Matching) # Estimation des effets de traitement causauxlibrary(progressr) # Suivi de progressionlibrary(glue) # Manipulation de textelibrary(rlang)library(car)library(tibble)library(qqplotr) # pour créer la bande de confiancelibrary(halfmoon)library(cobalt)library(ggpubr)matching_variables <-c("treecover_area_2000","slope_2000","elevation_2000","population_count_2000","traveltime_2000_2000")prep_matching <-function(df_final) { out <- df_final %>%filter(GROUP %in%c("Treatment","Control")) %>%mutate(treatment =if_else(GROUP =="Treatment", 1L, 0L)) missing_cols <-setdiff(matching_variables, names(out))if (length(missing_cols) >0) {message(">> Colonnes manquantes: ", paste(missing_cols, collapse=", ")) } out %>%drop_na(all_of(intersect(matching_variables, names(out))))}# supprimer toute ancienne version pour éviter le masquageif (exists("run_matching_year")) rm(run_matching_year)run_matching_year <-function(year, overwrite =list(gen=FALSE, match=FALSE)) {cat("\n=== Matching", year, "===\n") fin_path <-glue("data/derived/hr_{year}_final.rds")if (!file.exists(fin_path)) stop("Fichier introuvable: ", fin_path) dat <-readRDS(fin_path) dat_m <-prep_matching(dat) n_total <-nrow(dat) n_filt <-nrow(dat_m) n_treat <-sum(dat_m$treatment ==1, na.rm =TRUE) n_ctrl <-sum(dat_m$treatment ==0, na.rm =TRUE)cat(glue(">> N total={n_total}, après filtre/NA={n_filt}; ","Traités={n_treat}, ","Contrôles={n_ctrl}\n")) have_all_vars <-all(matching_variables %in%names(dat_m))cat(">> Toutes les covars présentes ? ", have_all_vars, "\n")if (n_filt <5||!have_all_vars) {warning(glue("Année {year}: données insuffisantes ou variables manquantes — on saute."))return(NULL) } X_match <- dat_m %>% sf::st_drop_geometry() %>% dplyr::select(all_of(matching_variables)) %>%as.data.frame() gen_path <-glue("data/derived/gen_match_model_{year}.rds") match_path <-glue("data/derived/matching_result_{year}.rds") matched_out_path <-glue("data/derived/data_matched_{year}.rds")# --- GenMatch --- used_cache_gen <-FALSE t0 <-Sys.time()if (file.exists(gen_path) &&!isTRUE(overwrite$gen)) {cat(">> GenMatch: cache trouvé -> lecture\n") gen_model <-readRDS(gen_path) used_cache_gen <-TRUE } else {cat(">> GenMatch: calcul en cours...\n") gen_model <-GenMatch(Tr = dat_m$treatment,X = X_match,BalanceMatrix = X_match,estimand ="ATT",M =1,weights =NULL,pop.size =1000,max.generations =100,wait.generations =4,caliper = .25,print.level =1,cluster =rep("localhost", 4) )saveRDS(gen_model, gen_path) } t_gen <-as.numeric(difftime(Sys.time(), t0, units="mins"))cat(glue(">> GenMatch temps = {round(t_gen,1)} min (cache={used_cache_gen})\n"))# --- matchit() --- used_cache_match <-FALSE t1 <-Sys.time()if (file.exists(match_path) &&!isTRUE(overwrite$match)) {cat(">> matchit: cache trouvé → lecture\n") m_out <-readRDS(match_path) used_cache_match <-TRUE } else {cat(">> matchit: calcul en cours...\n") fml <-as.formula(paste("treatment ~", paste(matching_variables, collapse=" + "))) m_out <-matchit(formula = fml,data = dat_m,method ="genetic",distance ="mahalanobis",gen.match = gen_model )saveRDS(m_out, match_path) } matched <-match.data(m_out, data = sf::st_drop_geometry(dat_m)) %>% dplyr::filter(weights >0)saveRDS(matched, matched_out_path)cat(glue(">> N appariés = {nrow(matched)} (écrit: {matched_out_path})\n"))tibble( Année = year,'Total des observations'= n_total,'Après filtre/NA'= n_filt, Traités = n_treat, Contrôles = n_ctrl,'N appariés'=nrow(matched) )}need_overwrite <-function(year) { gen_path <-glue("data/derived/gen_match_model_{year}.rds") match_path <-glue("data/derived/matching_result_{year}.rds")list(gen =!file.exists(gen_path), match =!file.exists(match_path))}# --- Exécution avec progression ---yrs <-c(1997, 2008, 2011, 2013, 2016, 2021)res_list <-vector("list", length(yrs))names(res_list) <- yrswith_progress({ p <-progressor(along = yrs)for (i inseq_along(yrs)) { yr <- yrs[i] ow <-need_overwrite(yr) cat(glue("\n>> overwrite {yr}: gen={ow$gen}, match={ow$match}\n"))cat(sprintf("Start %s", yr)) t_all <-Sys.time() res_list[[i]] <-tryCatch(run_matching_year(yr, overwrite = ow),error =function(e) { warning(glue("Year {yr} ERROR: {e$message}")); NULL } )cat(sprintf("Done %s (%.1f min)", yr, as.numeric(difftime(Sys.time(), t_all, units="mins"))))}})
>> overwrite 1997: gen=FALSE, match=FALSEStart 1997
=== Matching 1997 ===
>> N total=5124, après filtre/NA=4470; Traités=965, Contrôles=3505>> Toutes les covars présentes ? TRUE
>> GenMatch: cache trouvé -> lecture
>> GenMatch temps = 0 min (cache=TRUE)>> matchit: cache trouvé → lecture
>> N appariés = 1930 (écrit: data/derived/data_matched_1997.rds)Done 1997 (0.0 min)>> overwrite 2008: gen=FALSE, match=FALSEStart 2008
=== Matching 2008 ===
>> N total=13364, après filtre/NA=11726; Traités=2451, Contrôles=9275>> Toutes les covars présentes ? TRUE
>> GenMatch: cache trouvé -> lecture
>> GenMatch temps = 0 min (cache=TRUE)>> matchit: cache trouvé → lecture
>> N appariés = 4902 (écrit: data/derived/data_matched_2008.rds)Done 2008 (0.0 min)>> overwrite 2011: gen=FALSE, match=FALSEStart 2011
=== Matching 2011 ===
>> N total=6025, après filtre/NA=5151; Traités=930, Contrôles=4221>> Toutes les covars présentes ? TRUE
>> GenMatch: cache trouvé -> lecture
>> GenMatch temps = 0 min (cache=TRUE)>> matchit: cache trouvé → lecture
>> N appariés = 1860 (écrit: data/derived/data_matched_2011.rds)Done 2011 (0.0 min)>> overwrite 2013: gen=FALSE, match=FALSEStart 2013
=== Matching 2013 ===
>> N total=6375, après filtre/NA=5533; Traités=1539, Contrôles=3994>> Toutes les covars présentes ? TRUE
>> GenMatch: cache trouvé -> lecture
>> GenMatch temps = 0 min (cache=TRUE)>> matchit: cache trouvé → lecture
>> N appariés = 3078 (écrit: data/derived/data_matched_2013.rds)Done 2013 (0.0 min)>> overwrite 2016: gen=FALSE, match=FALSEStart 2016
=== Matching 2016 ===
>> N total=9295, après filtre/NA=8456; Traités=1685, Contrôles=6771>> Toutes les covars présentes ? TRUE
>> GenMatch: cache trouvé -> lecture
>> GenMatch temps = 0 min (cache=TRUE)>> matchit: cache trouvé → lecture
>> N appariés = 3370 (écrit: data/derived/data_matched_2016.rds)Done 2016 (0.0 min)>> overwrite 2021: gen=FALSE, match=FALSEStart 2021
=== Matching 2021 ===
>> N total=15364, après filtre/NA=13405; Traités=3392, Contrôles=10013>> Toutes les covars présentes ? TRUE
>> GenMatch: cache trouvé -> lecture
>> GenMatch temps = 0 min (cache=TRUE)>> matchit: cache trouvé → lecture
>> N appariés = 6784 (écrit: data/derived/data_matched_2021.rds)Done 2021 (0.0 min)
Nous obtenons un tableau qui présente, pour chaque année d’analyse, le nombre total d’observations initialement disponibles, le nombre d’observations conservées après exclusion des observations ne relevant ni du groupe Treatment ni du groupe Control, ainsi que celles présentant des valeurs manquantes sur les variables utilisées pour le matching. Le tableau indique également les effectifs des groupes traités et contrôles avant et après le matching.
8.3 Checking covariate balance
Les modèles d’appariement reposent sur l’hypothèse que les distributions des covariables sont similaires entre les groupes de traitement et de contrôle, rendant cruciale l’évaluation de l’équilibre des covariables. La validité des estimations dépend directement de la qualité de cet équilibre, d’où l’importance de réaliser des tests pour le mesurer. On effectue donc un test d’équilibre des covariables en deux étapes: un test avant appariement et un test après appariement.
8.3.0.1 Balance test before matching
Pour effectuer le test avant l’appariement, on détermine les déséquilibres initiaux à partir du test de Standardized Mean Difference (SMD). Le SMD mesure l’écart entre les moyennes des covariables dans les groupes de traitement et les groupes de contrôle pour comparer l’équilibre relatif des variables mesurées dans des unités différentes:
Si |SMD| < 0.1, il existe un équilibre satisfaisant entre les groupes pour la covariable.
Si SMD > 0.1, le déséquilibre est significatif (Austin 2009). Pour réajuster l’équilibre, on augmentera l’intervalle des calipers afin d’obtenir un SMD ≤ 0.1.
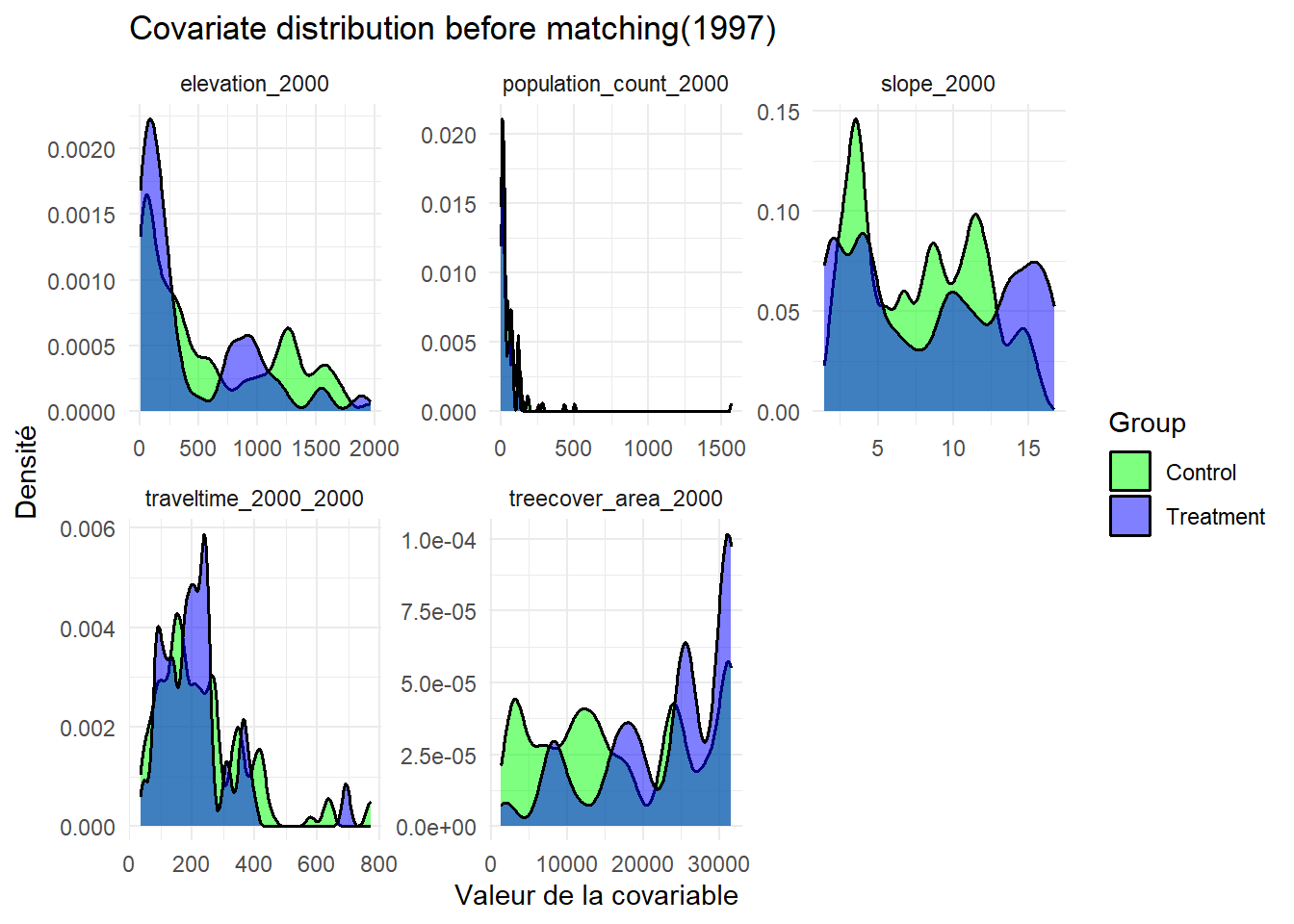
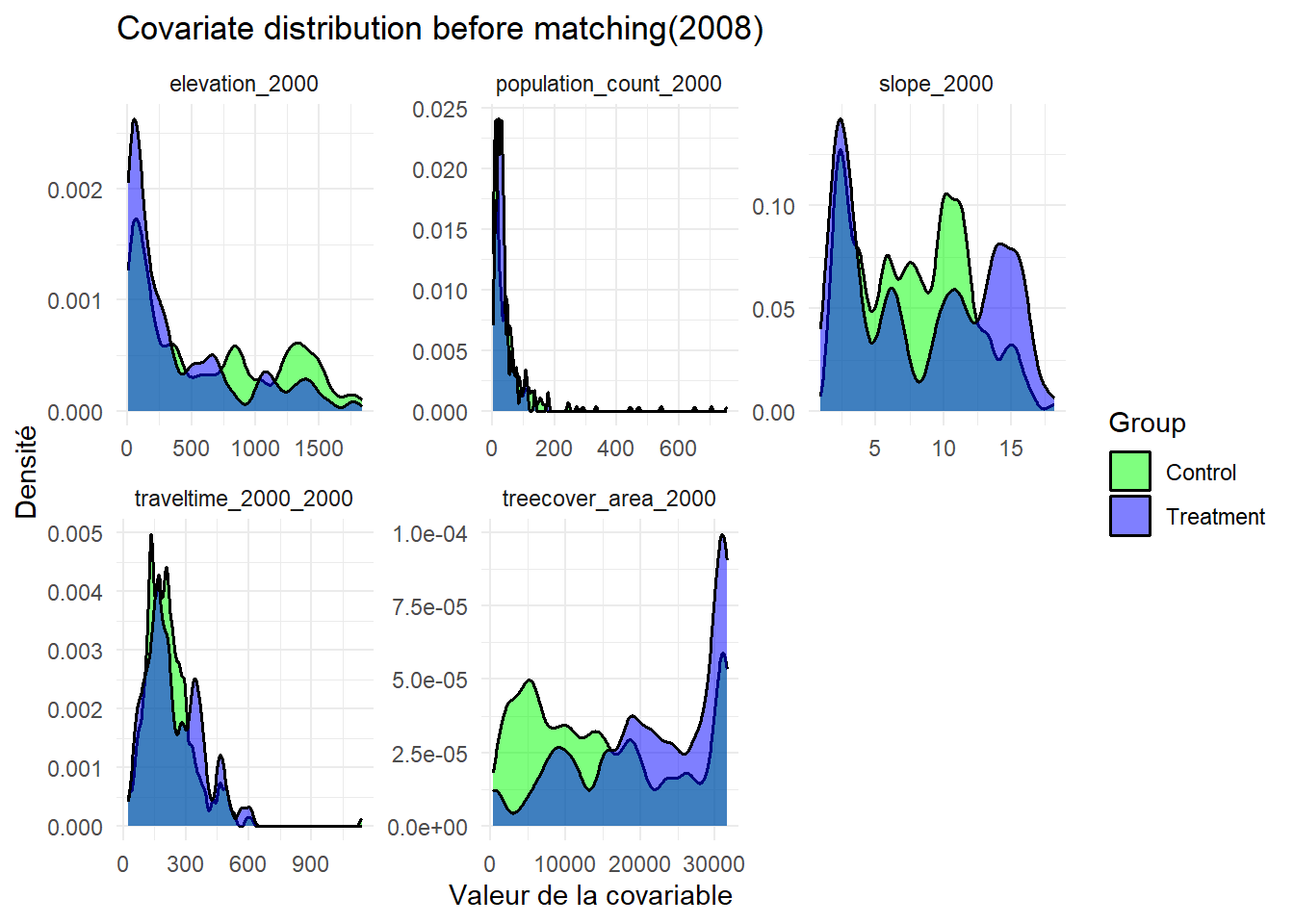
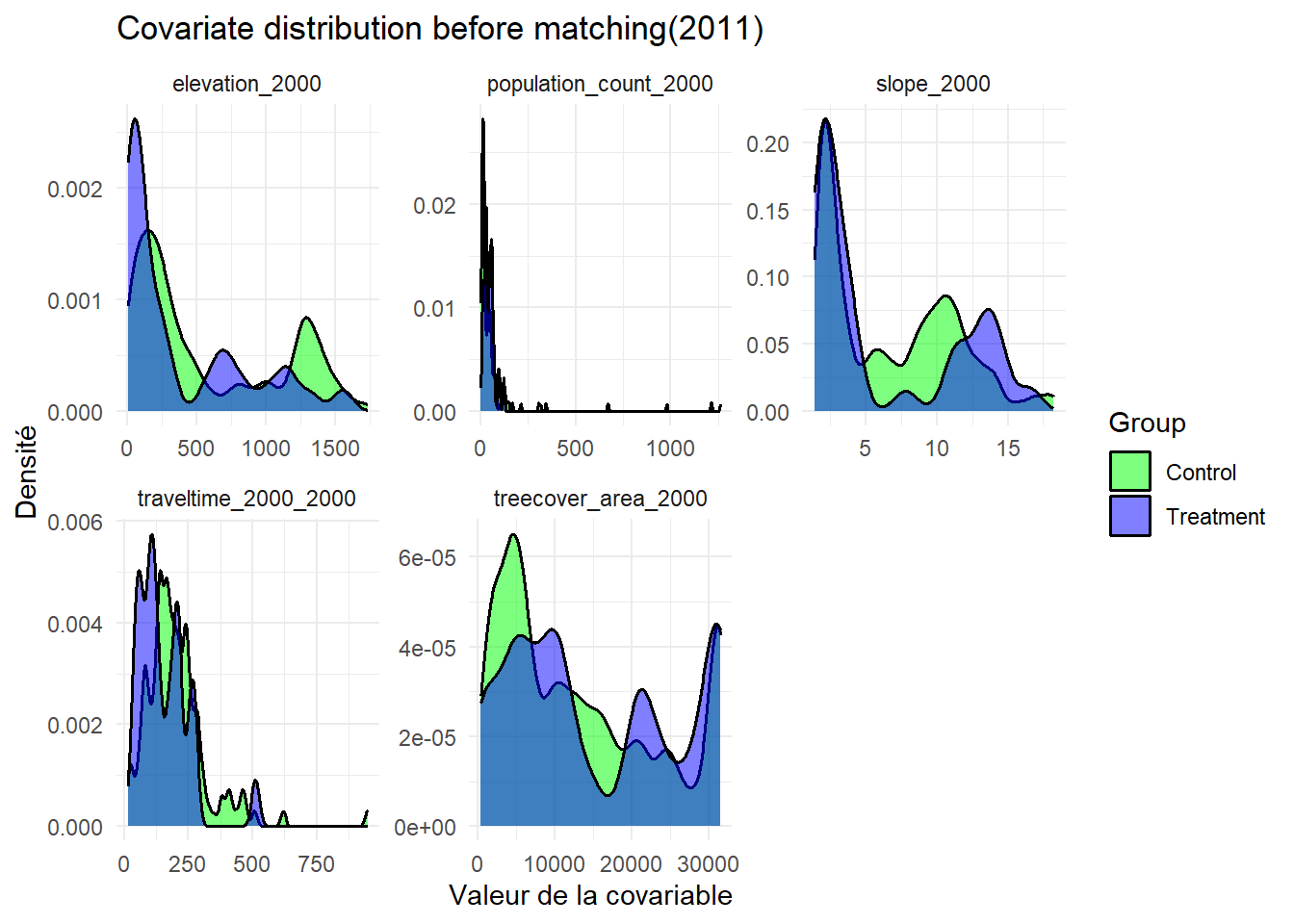
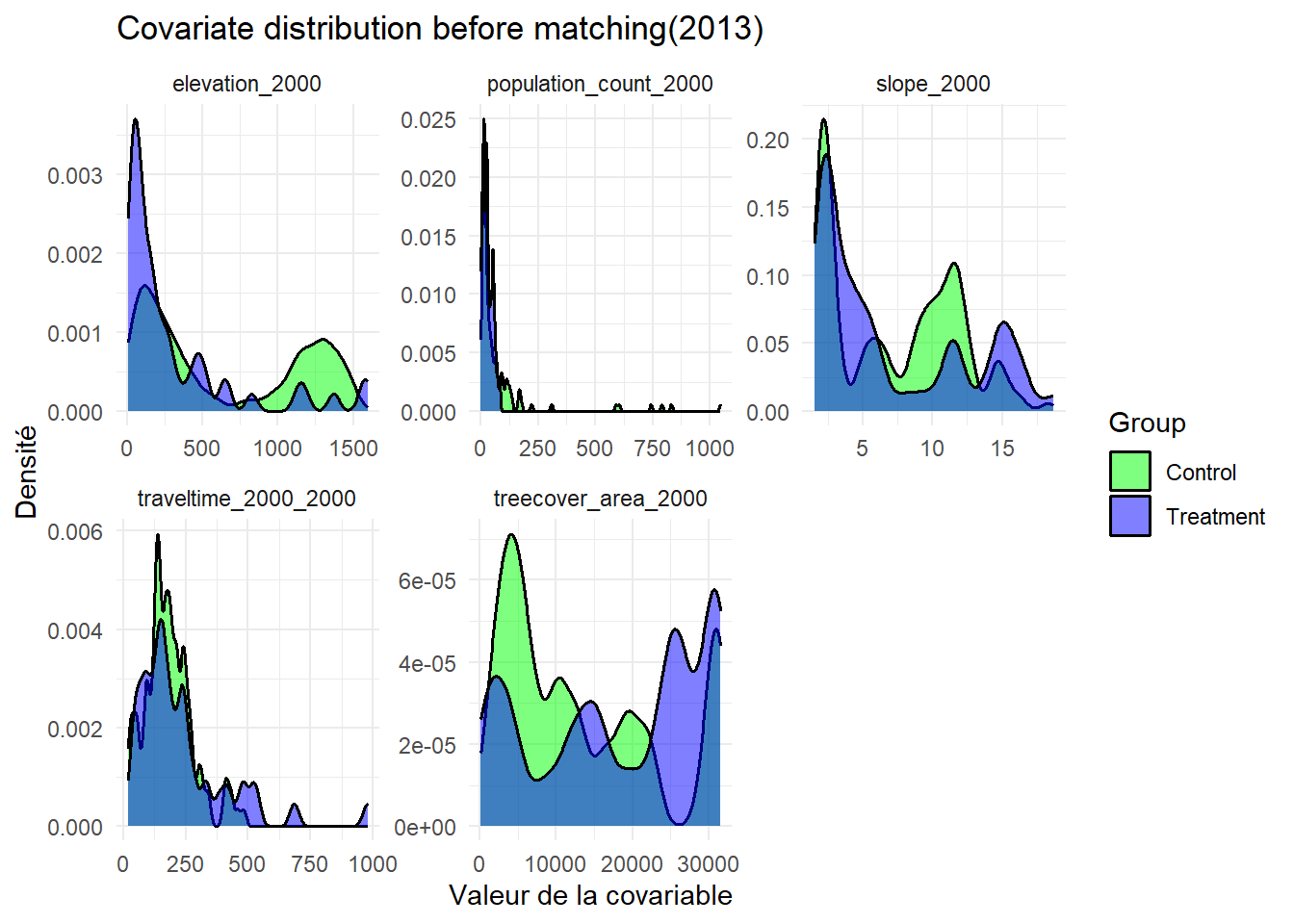
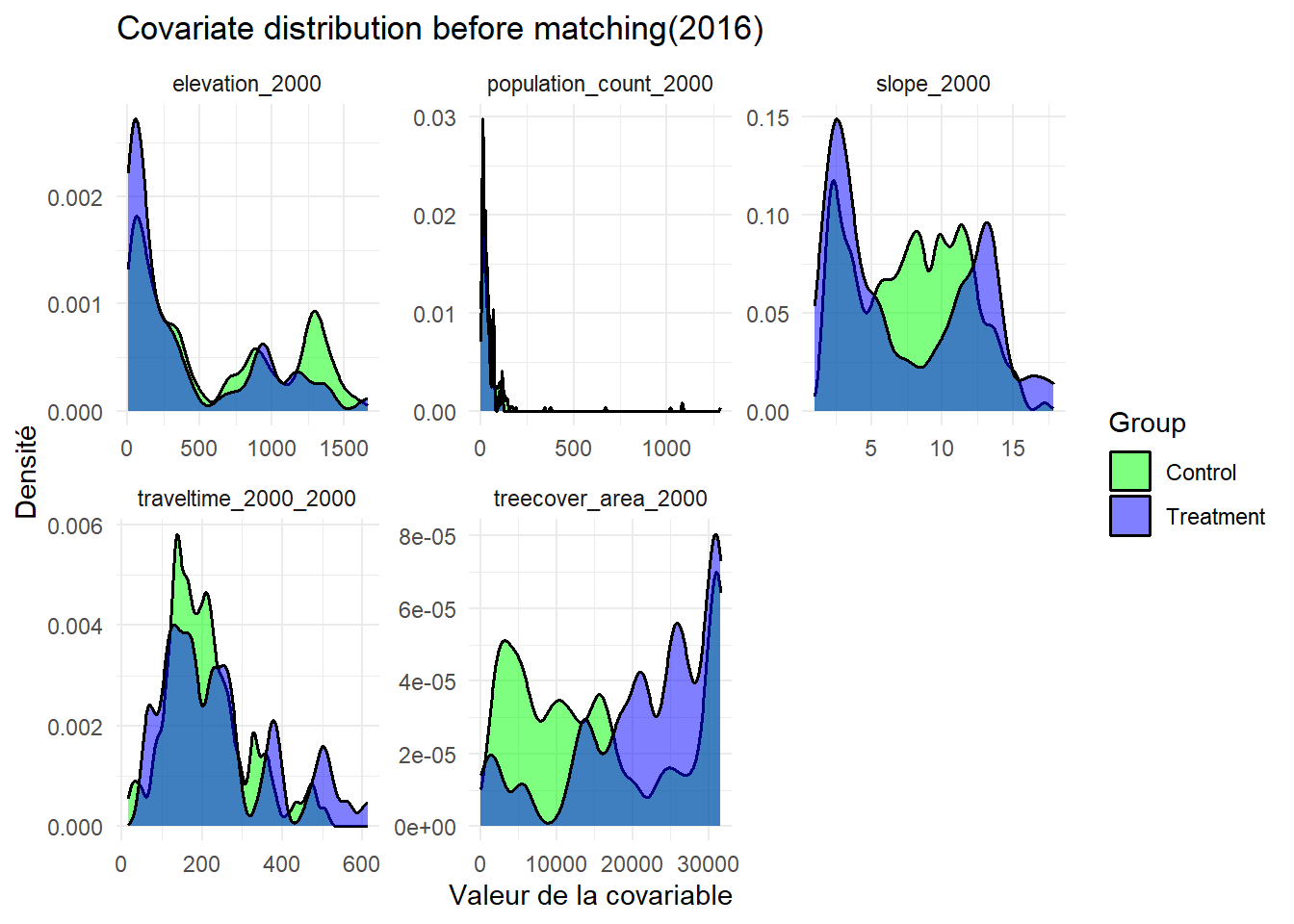
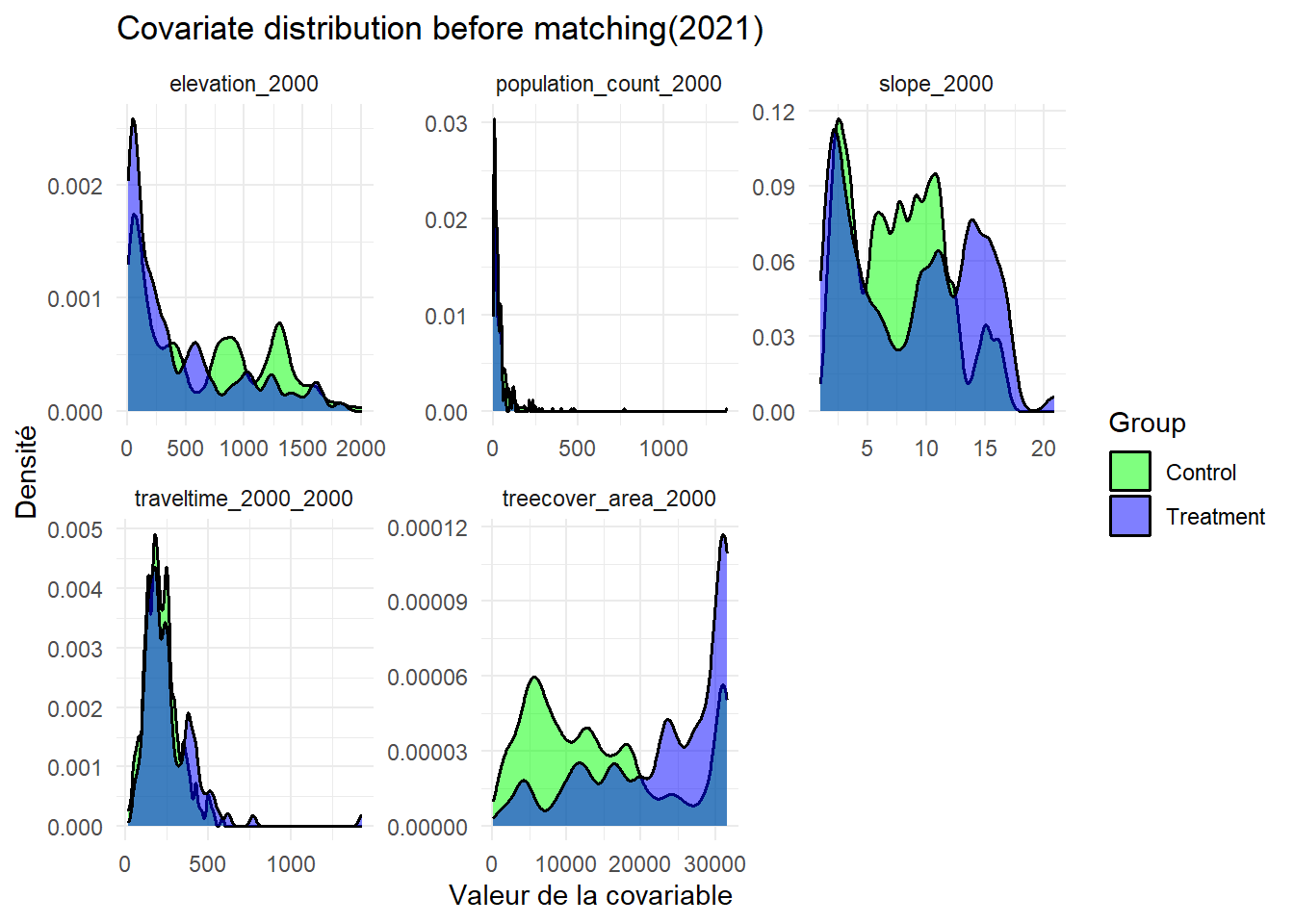
L’analyse des distributions des covariables avant le matching montrent un déséquilibre important entre les groupes de traitement et de contrôle. En 1997, l’équilibre des covariables est partiellement atteint. Deux variables montrent un déséquilibre dont la couverture forestière en 2000 (avec un SMD = 0.15) et l’accessibilité en 2000 (avec un SMD = 0.17). Cela montre des différences structurelles persistantes entre les groupes. En 2008, l’équilibre est globalement satisfaisant, avec un léger déséquilibre pour la variable densité de population avec un SMD égale à 0.10, tandis que l’ensemble des autres covariables présente un SMD inférieur à 0.05. En 2011, tous les covariables sont bien équilibrées sauf pour la variable densité de population. Cette dernière montre un déséquilibre modéré dont la SMD est égale à 0.15. Cela suggère une certaine hétérogénéité territoriale entre les zones traitées et non traitées. Cette année est celle où le matching est le plus performant. En 2013, la majorité des covariables sont équilibrées mais le temps de déplacement reste déséquilibré avec un SMD égale à 0.14. Cela indique l’existence d’une différence persistante d’accessibilité entre les groupes. En 2016, toutes les covariables présentent un SMD inférieur au seuil de 0.1, qui indique un équilibre satisfaisant entre les groupes. En 2021, plusieurs covariables présentent un léger déséquilibre. Les groupes restent structurellement différents en termes de contexte géographique et socio-démographique.
Code
# Load data before matchinghr_1997_final <-readRDS("data/derived/hr_1997_final.rds")hr_2008_final <-readRDS("data/derived/hr_2008_final.rds")hr_2011_final <-readRDS("data/derived/hr_2011_final.rds")hr_2013_final <-readRDS("data/derived/hr_2013_final.rds")hr_2016_final <-readRDS("data/derived/hr_2016_final.rds")hr_2021_final <-readRDS("data/derived/hr_2021_final.rds")# Distribution des covariablesdata_list <-list("1997"= hr_1997_final,"2008"= hr_2008_final,"2011"= hr_2011_final,"2013"= hr_2013_final,"2016"= hr_2016_final,"2021"= hr_2021_final ) density_plot <-function(data, year, matching_variables){ data %>%filter(GROUP %in%c("Treatment", "Control")) %>%mutate(GROUP =factor(GROUP, levels =c("Control", "Treatment"))) %>%pivot_longer(cols =all_of(matching_variables), names_to ="variable", values_to ="value") %>%ggplot(aes(x = value, fill = GROUP)) +geom_density(alpha =0.5, color ="black", linewidth =0.7, adjust =0.7) +facet_wrap(~variable, scales ="free") +scale_fill_manual(values =c("Control"="green", "Treatment"="blue")) +labs(title =paste("Covariate distribution before matching(", year, ")", sep =""),x ="Valeur de la covariable",y ="Densité",fill ="Group" ) +theme_minimal() }print(density_plot(hr_1997_final, 1997, matching_variables))
Ces graphiques présentent la distribution des covariables avant le matching entre les clusters situés à proximité des aires protégées (en violet) et ceux qui en sont éloignés (vert). Chaque panneau illustre les covariables utilisées dans le matching à savoir le taux de couvert forestier en 2000, la pente et l’altitude, la densité de population en 2000, la pente , l’accessibilité en 2000 (temps estimé de trajet en voiture des ménages jusqu’aux villes les plus proches).
8.3.0.2 Balance test after matching: Quantile- quantile QQ Plot analysis
Le test après appariement sera un test visuel de la qualité du matching en comparant la distribution de chaque covariable à partir d’un plot. La méthode graphique offre une vue d’ensemble de la distribution des covariables. Le graphique facilite ainsi l’identification des déséquilibres à différents niveaux de la distribution. Lorsque les points Q-Q plot se situent près de la diagonale, le quantile des deux distributions sont similaires, signalant ainsi un bon équilibre. Si les points s’écartent de la diagonale, cela indique que la distribution de l’échantillon diffère de la distribution théorique.
Balance Measures
Type Diff.Un
treecover_area_2000 Contin. 0.1509
slope_2000 Contin. 0.0292
elevation_2000 Contin. 0.0635
population_count_2000 Contin. 0.0272
traveltime_2000_2000 Contin. 0.1718
Sample sizes
Control Treatment
All 965 965
Balance Measures
Type Diff.Un
treecover_area_2000 Contin. 0.0278
slope_2000 Contin. 0.0142
elevation_2000 Contin. 0.0249
population_count_2000 Contin. 0.1027
traveltime_2000_2000 Contin. 0.0044
Sample sizes
Control Treatment
All 2451 2451
Balance Measures
Type Diff.Un
treecover_area_2000 Contin. 0.0974
slope_2000 Contin. 0.0009
elevation_2000 Contin. 0.0083
population_count_2000 Contin. 0.1535
traveltime_2000_2000 Contin. 0.0081
Sample sizes
Control Treatment
All 930 930
Balance Measures
Type Diff.Un
treecover_area_2000 Contin. 0.0091
slope_2000 Contin. 0.0070
elevation_2000 Contin. 0.0169
population_count_2000 Contin. 0.0996
traveltime_2000_2000 Contin. 0.1431
Sample sizes
Control Treatment
All 1539 1539
Balance Measures
Type Diff.Un
treecover_area_2000 Contin. 0.0541
slope_2000 Contin. 0.0098
elevation_2000 Contin. 0.0684
population_count_2000 Contin. 0.0916
traveltime_2000_2000 Contin. 0.0721
Sample sizes
Control Treatment
All 1685 1685
Balance Measures
Type Diff.Un
treecover_area_2000 Contin. 0.0593
slope_2000 Contin. 0.1149
elevation_2000 Contin. 0.1160
population_count_2000 Contin. 0.1093
traveltime_2000_2000 Contin. 0.0625
Sample sizes
Control Treatment
All 3392 3392
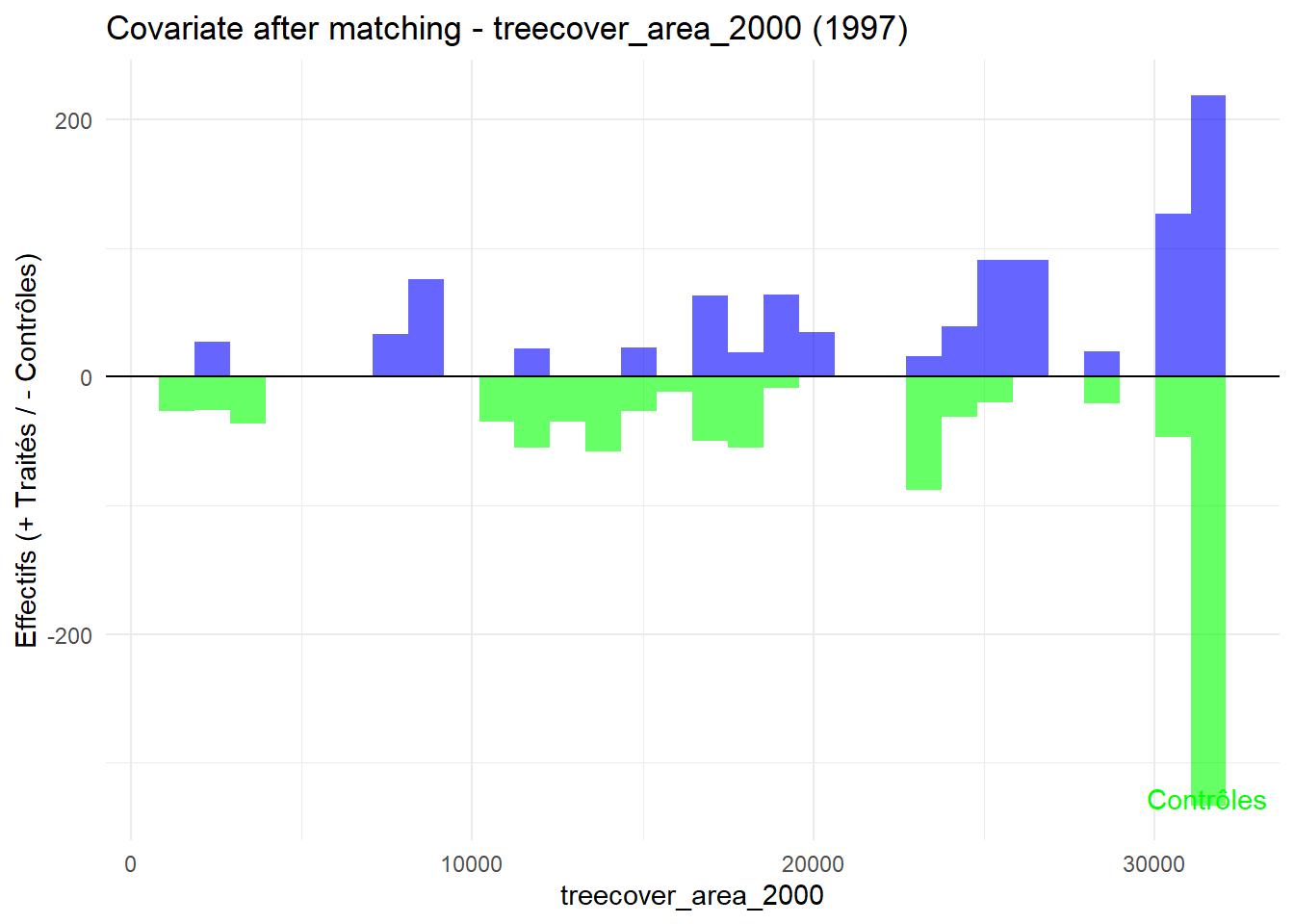
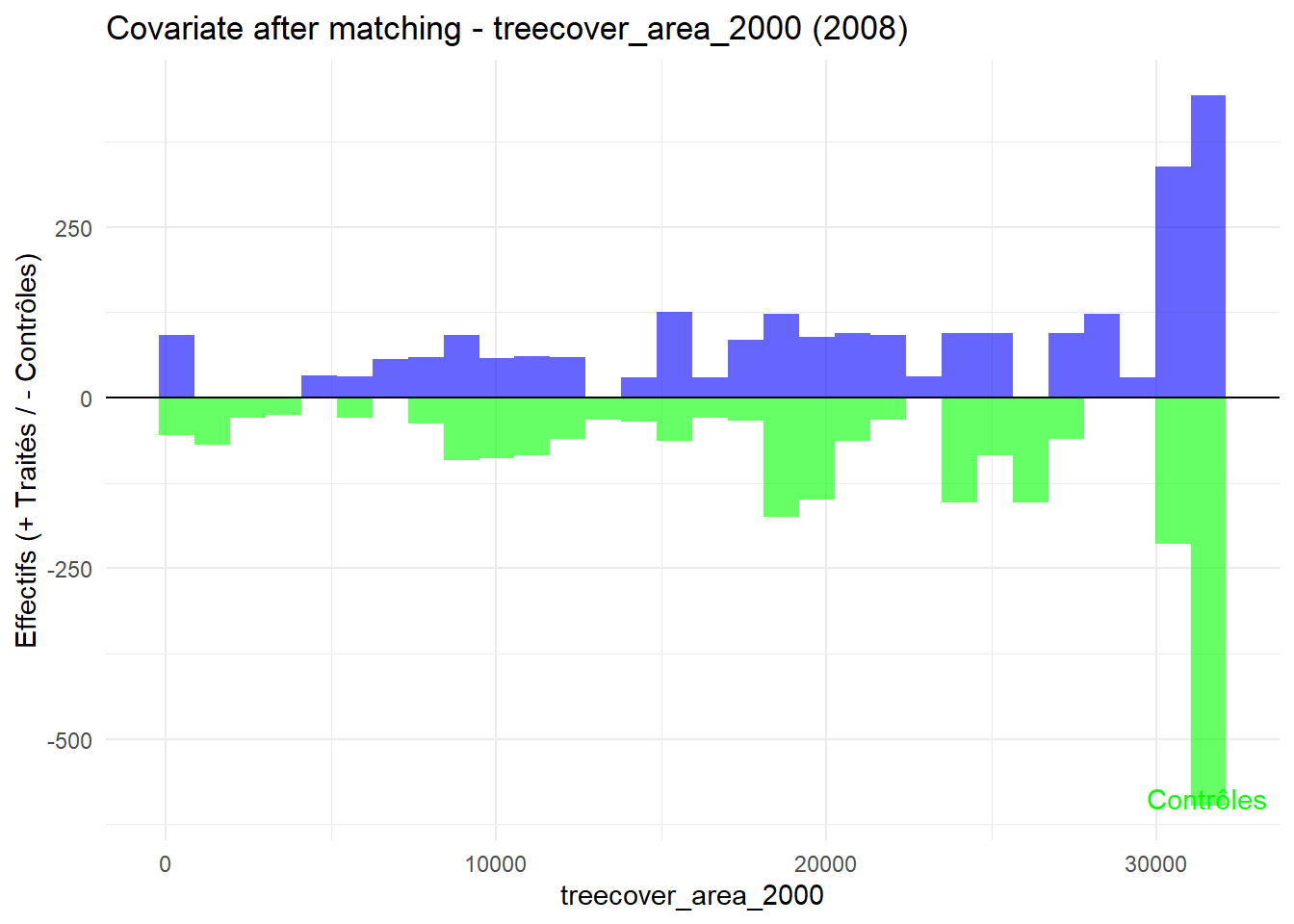
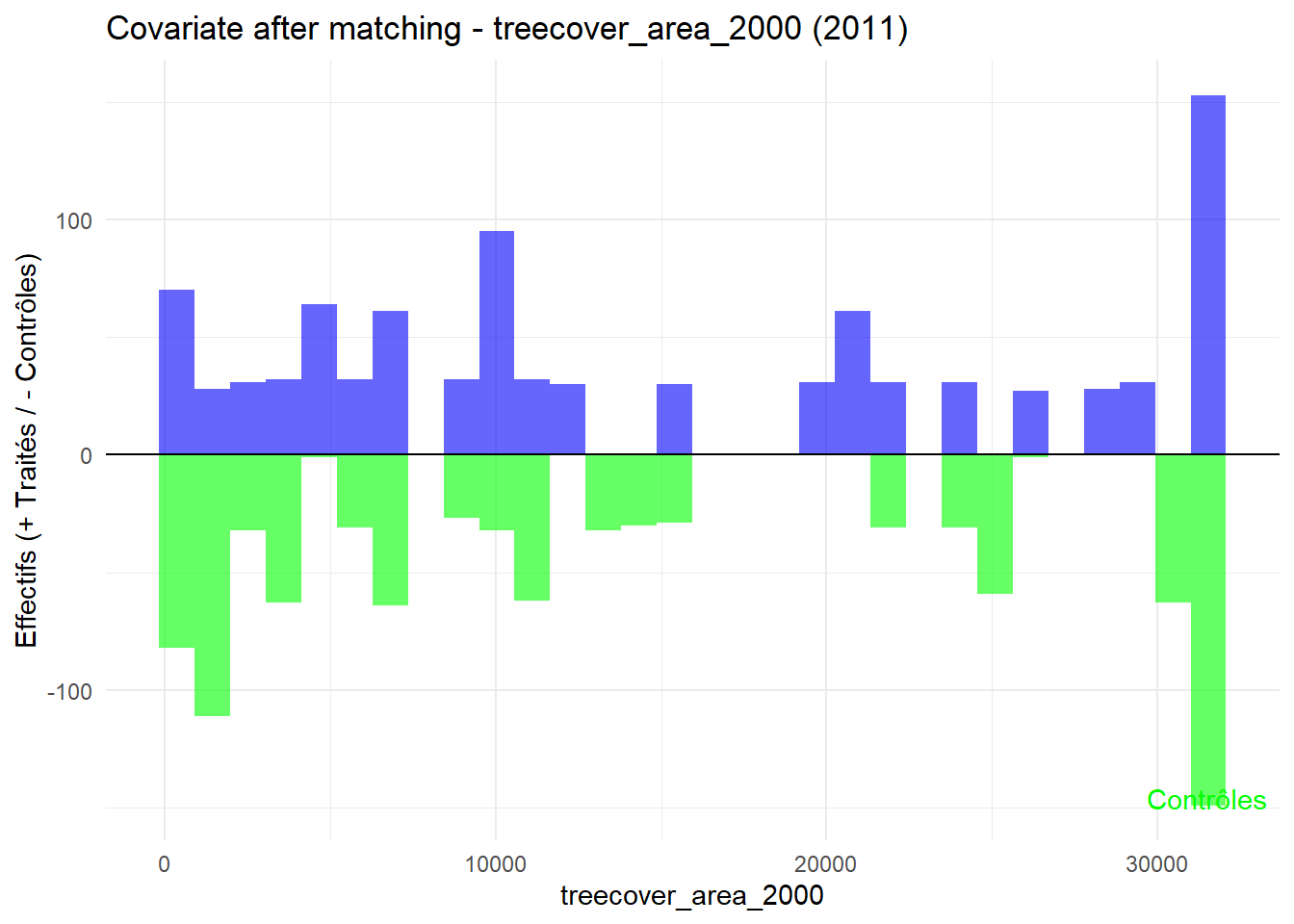
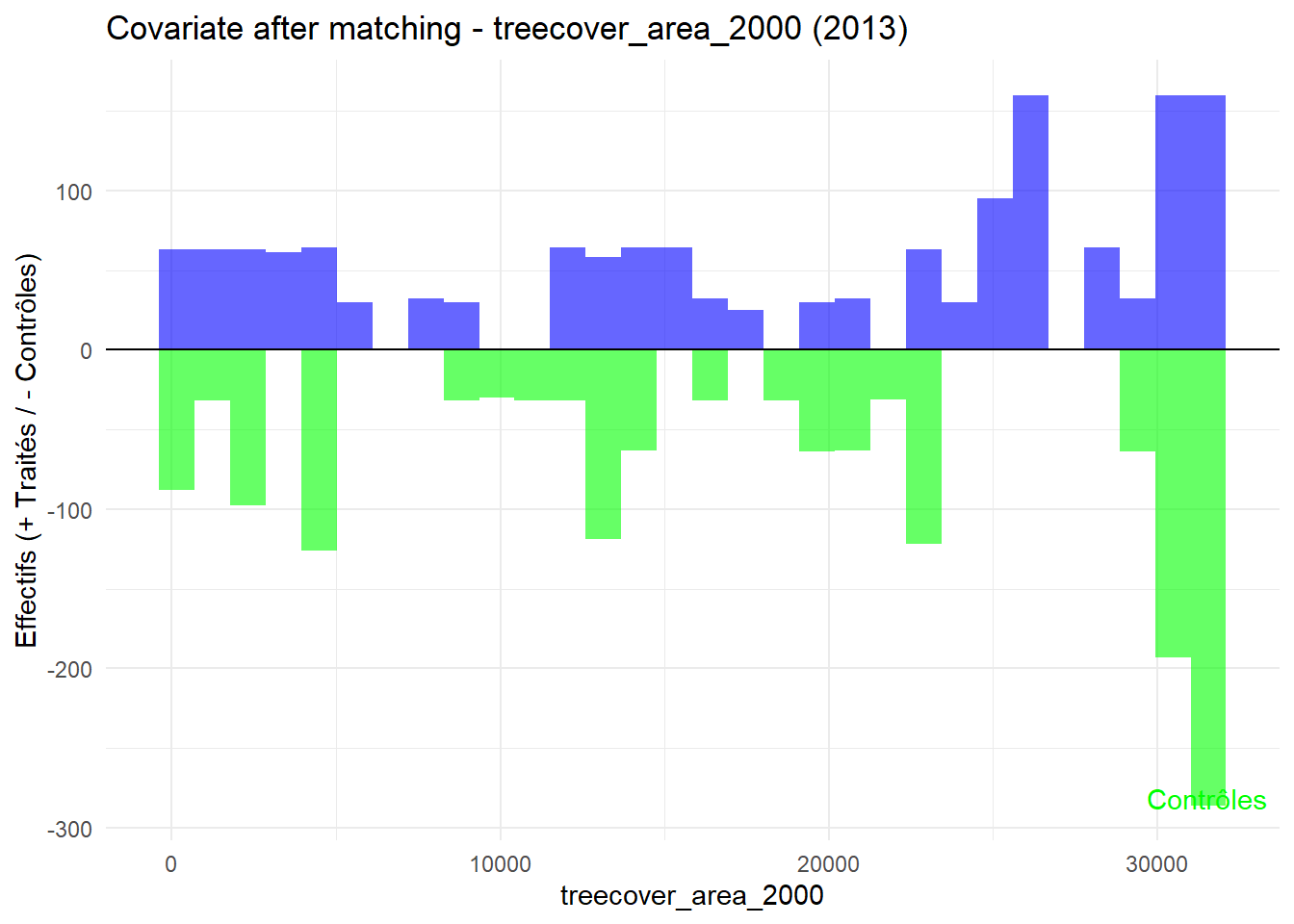
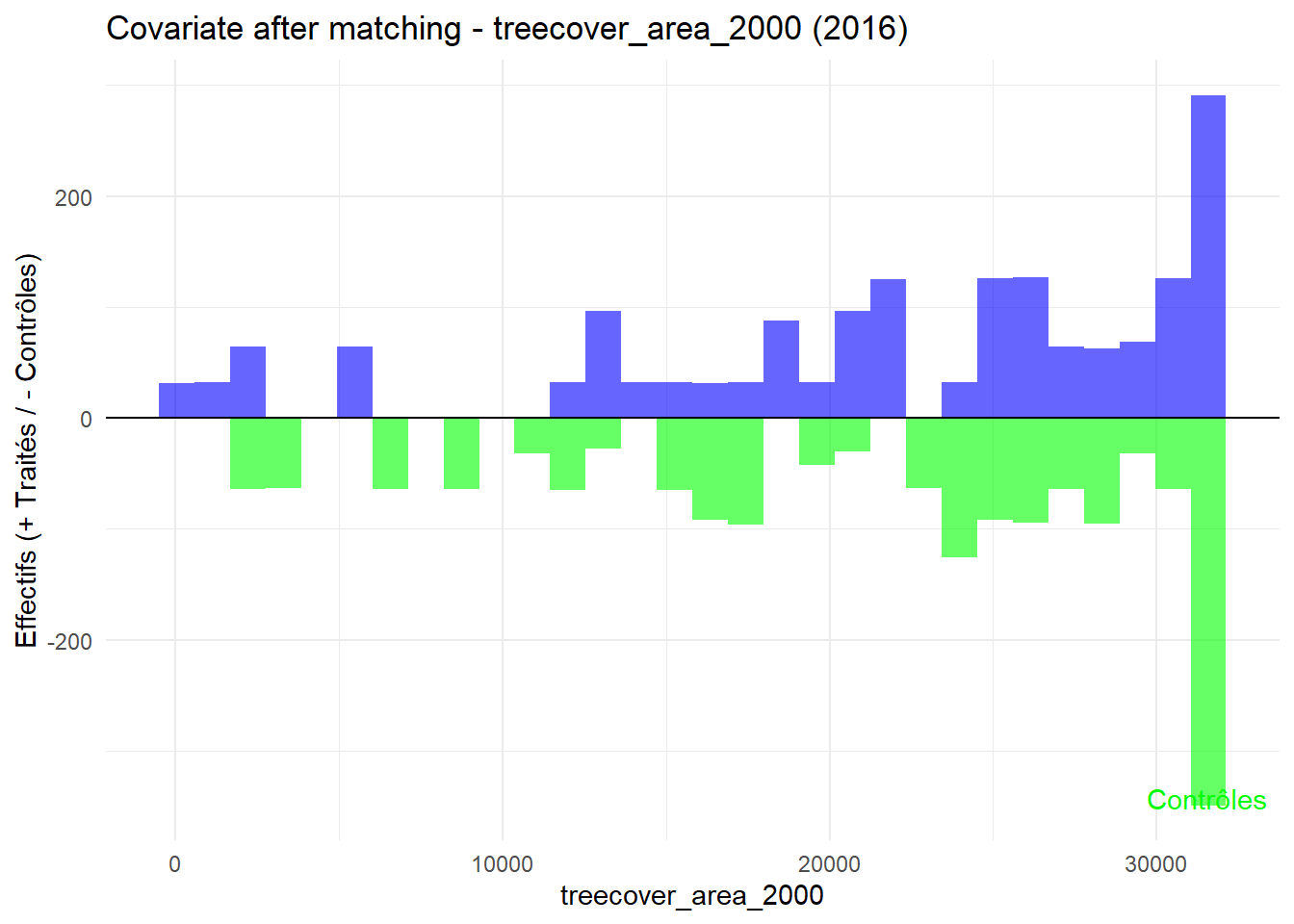
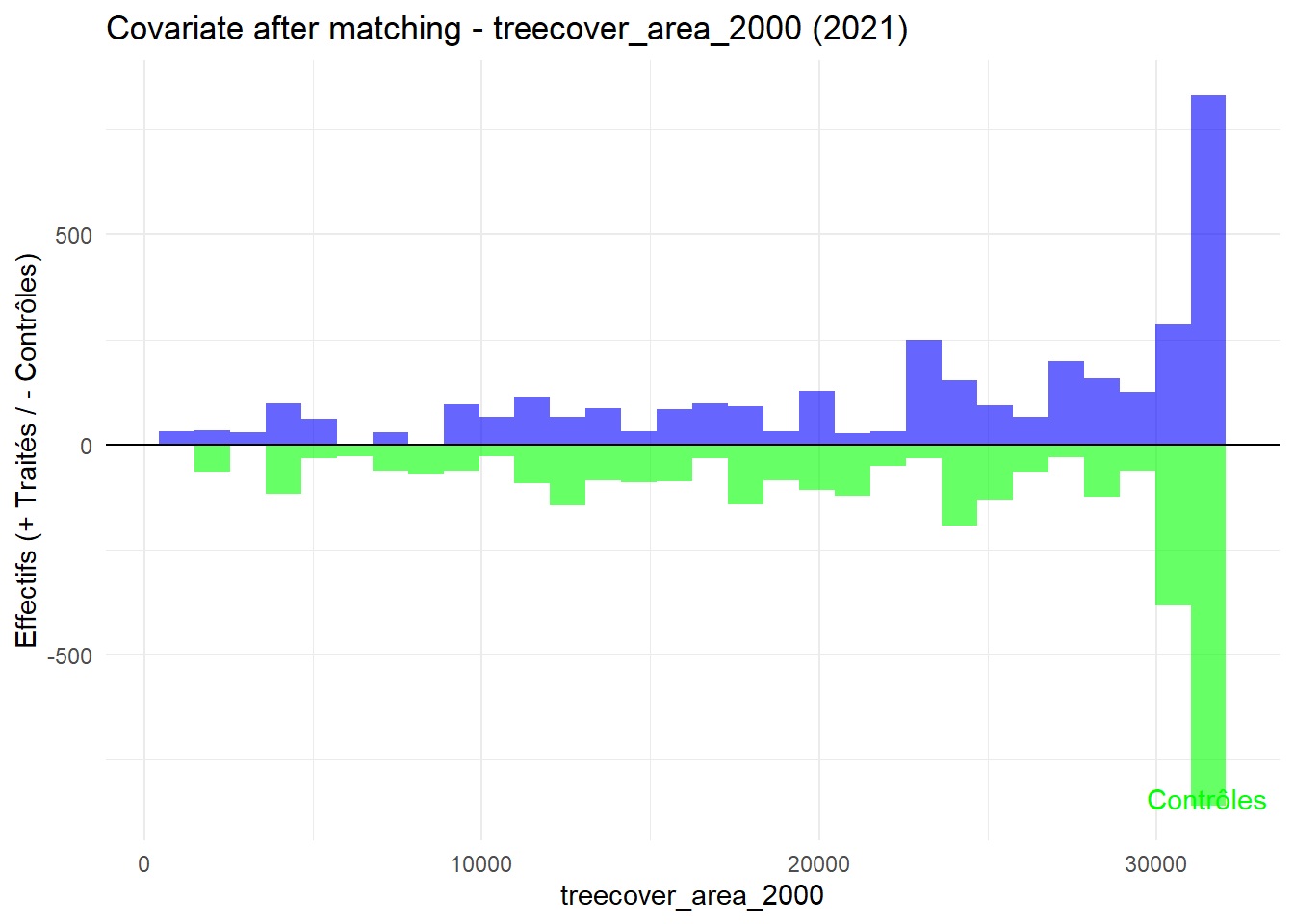
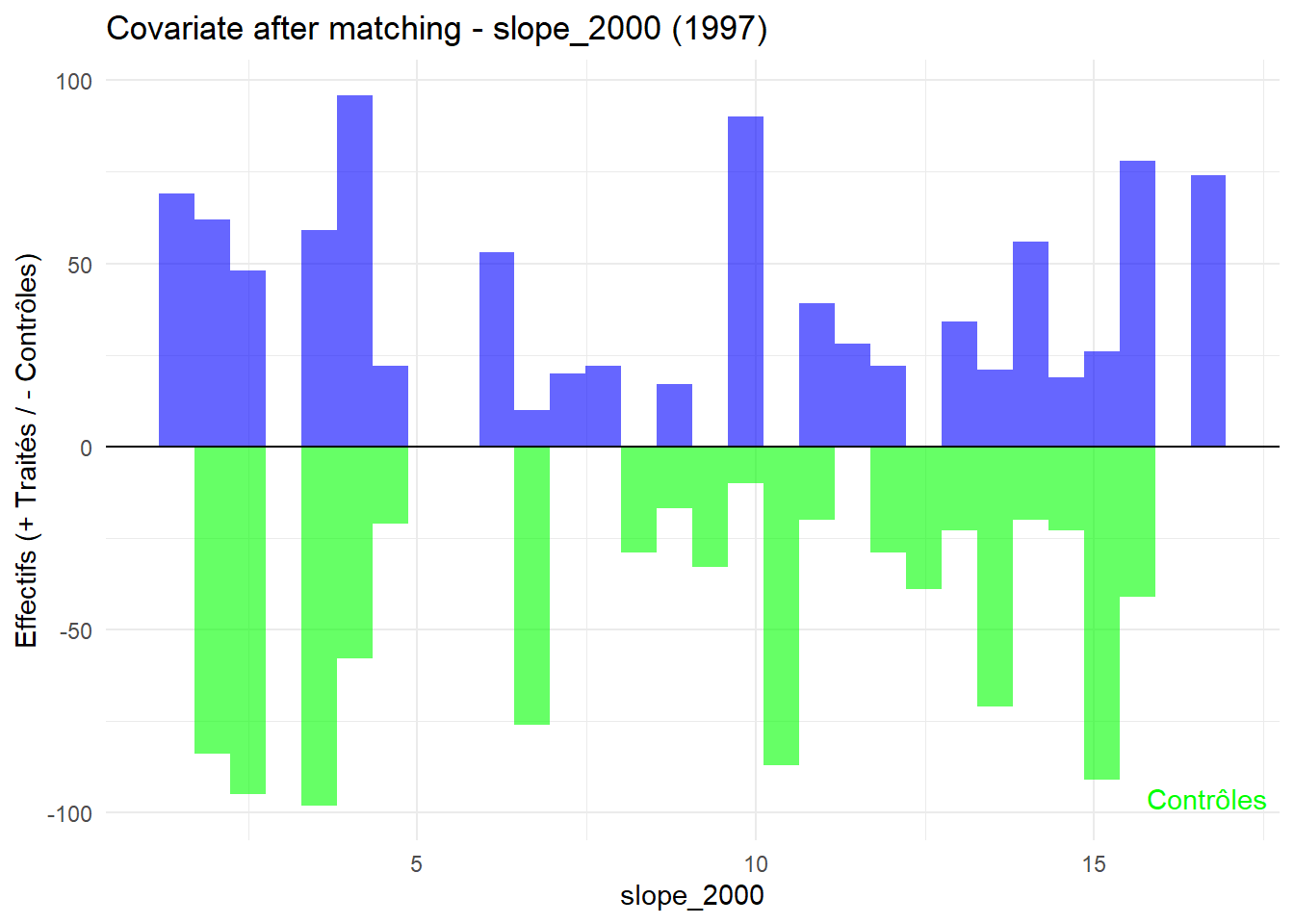
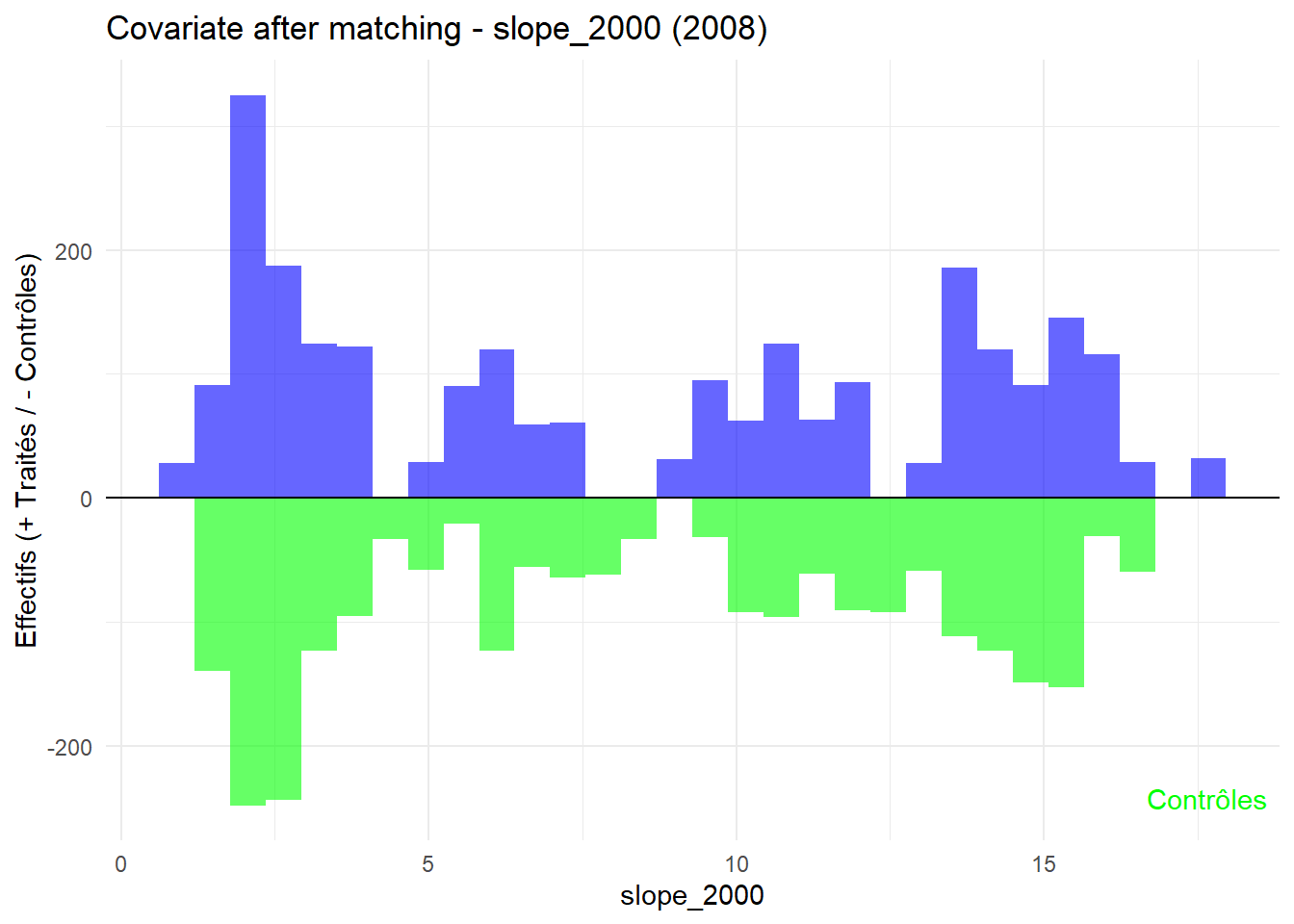
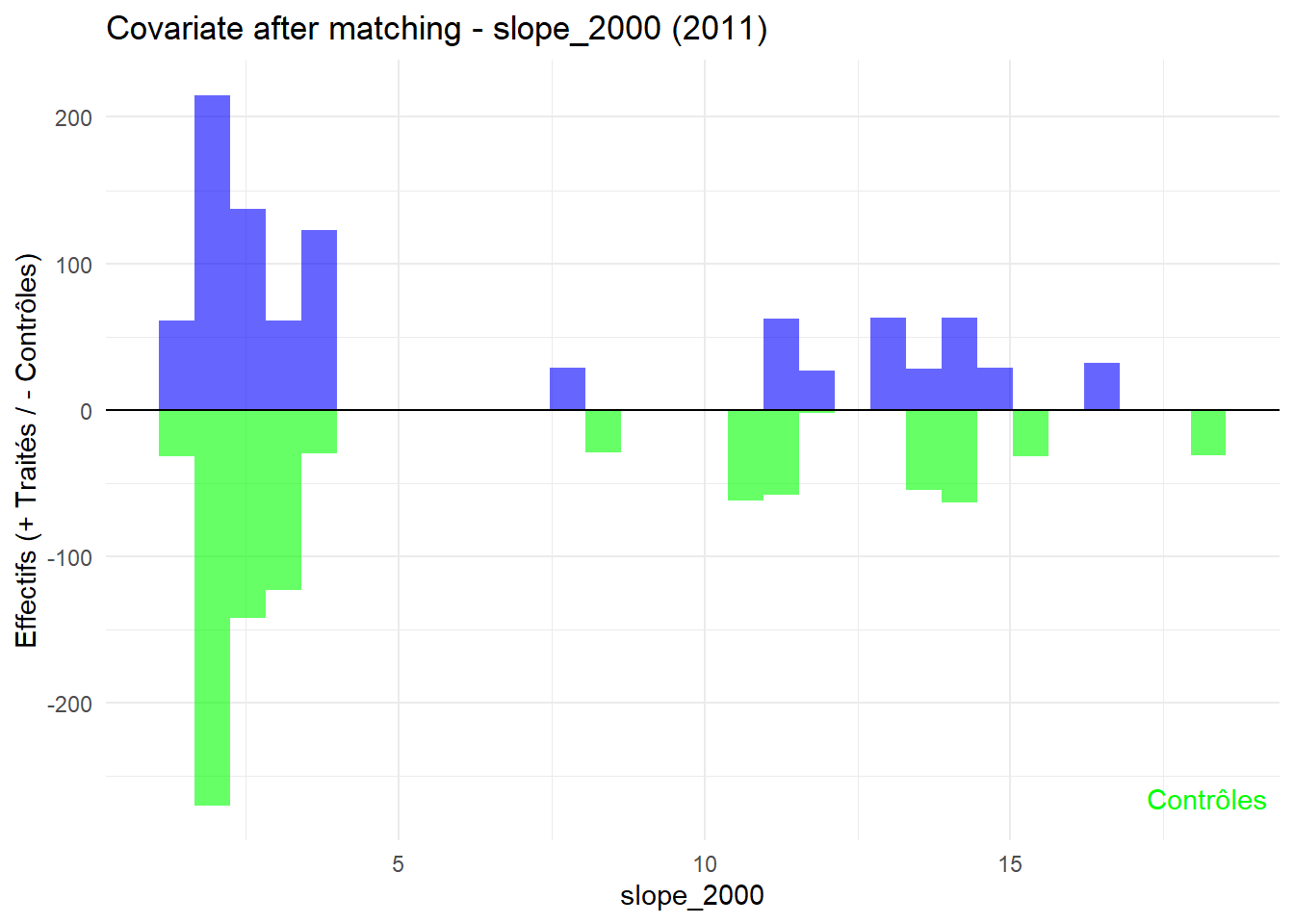
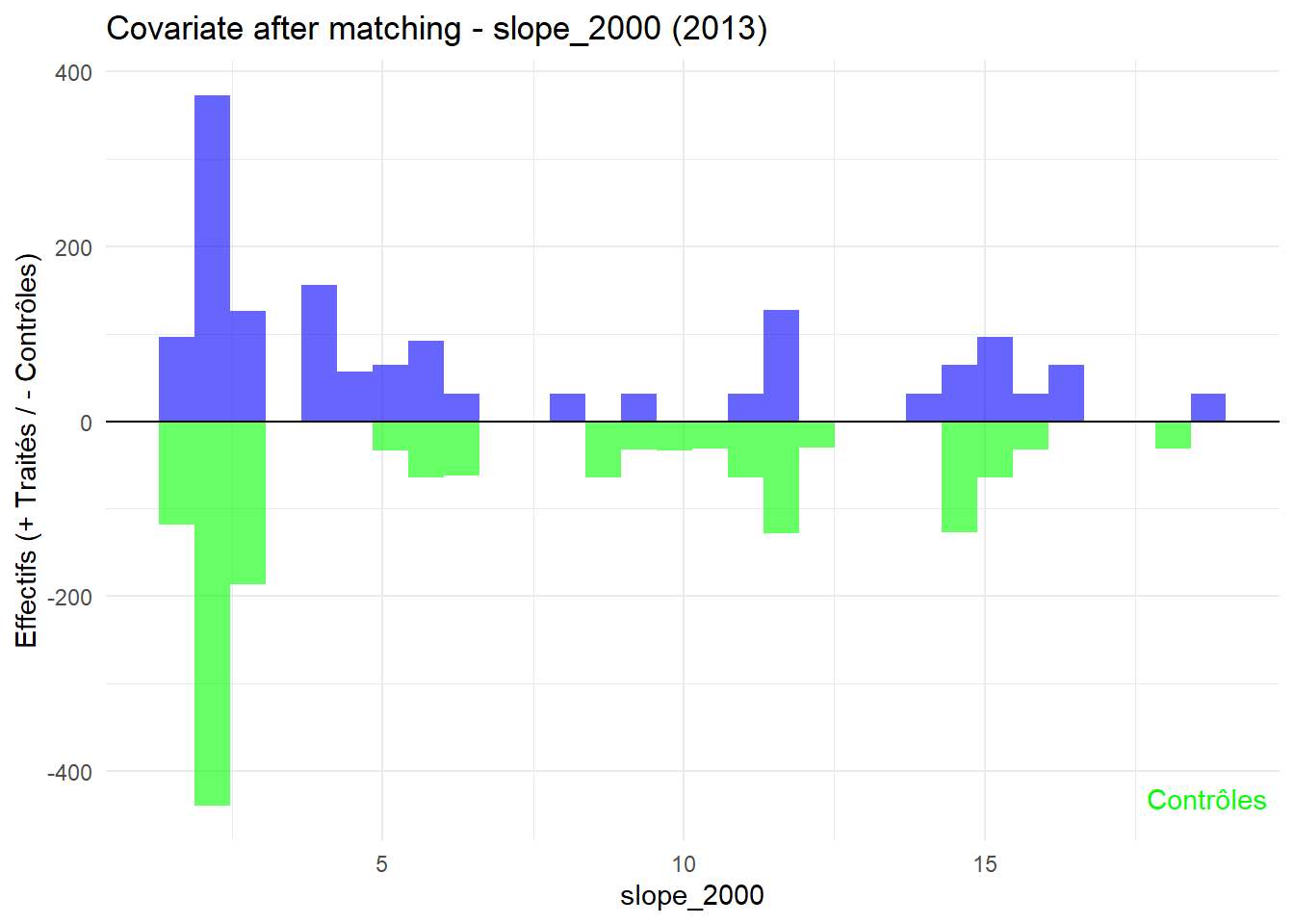
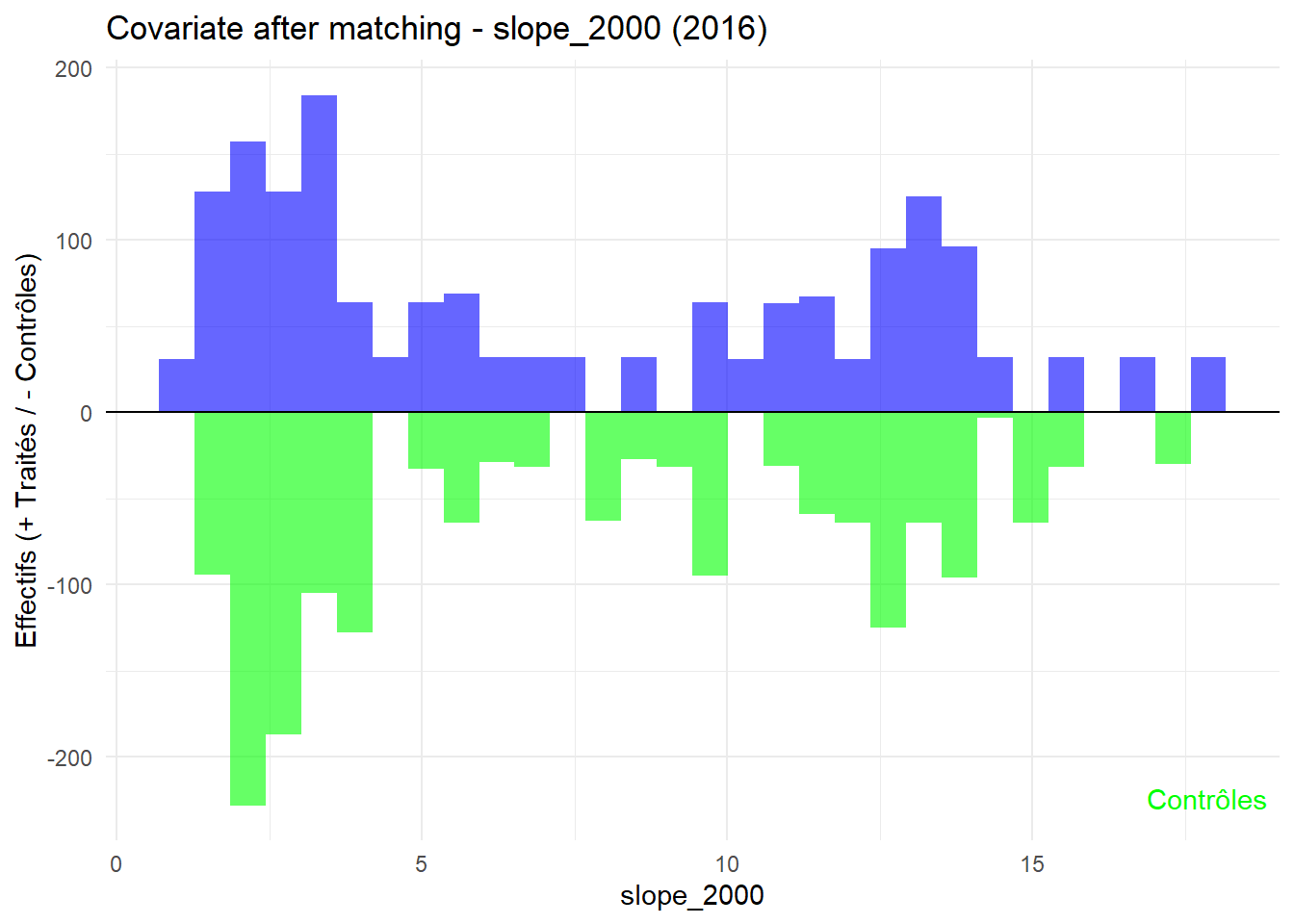
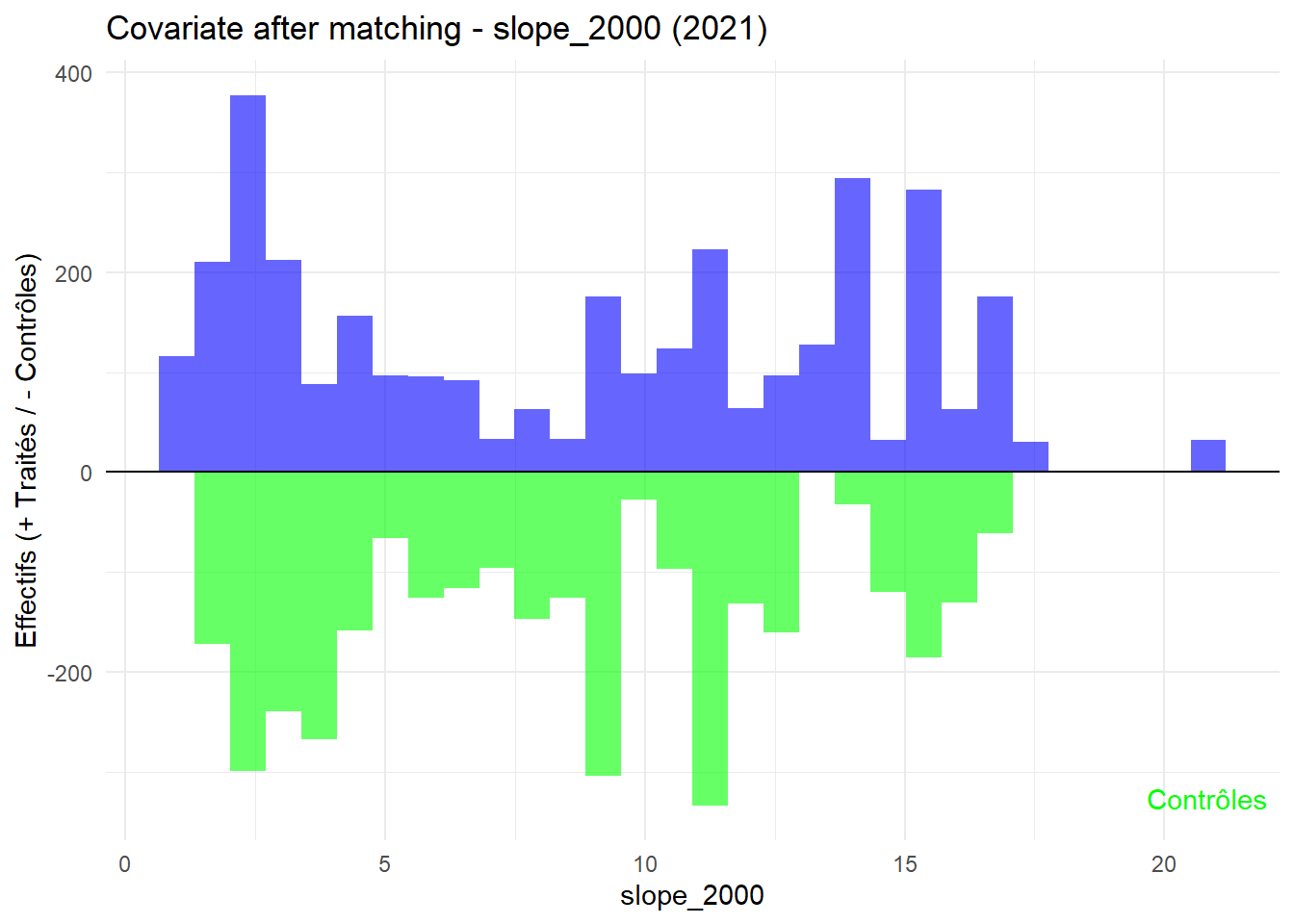
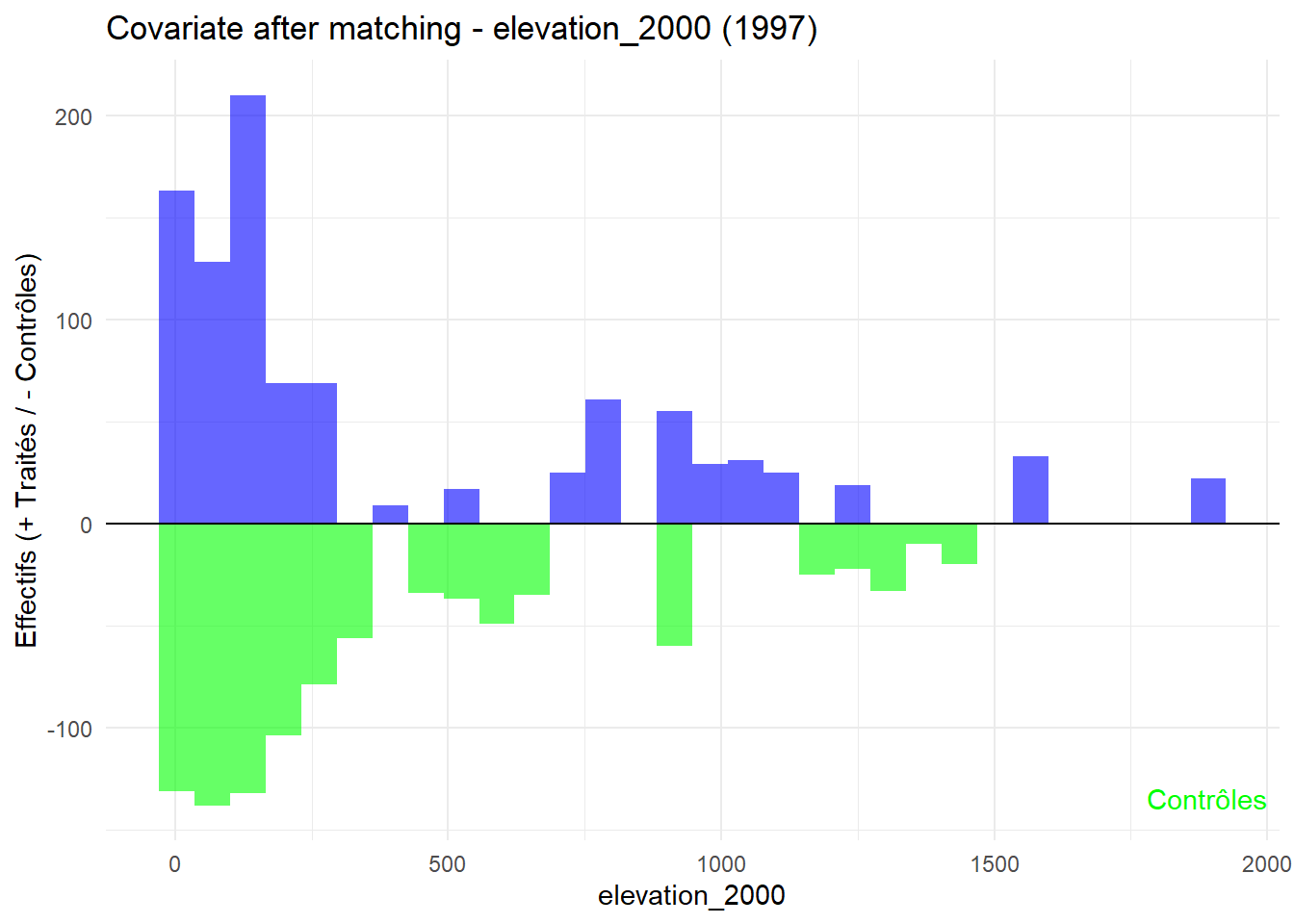
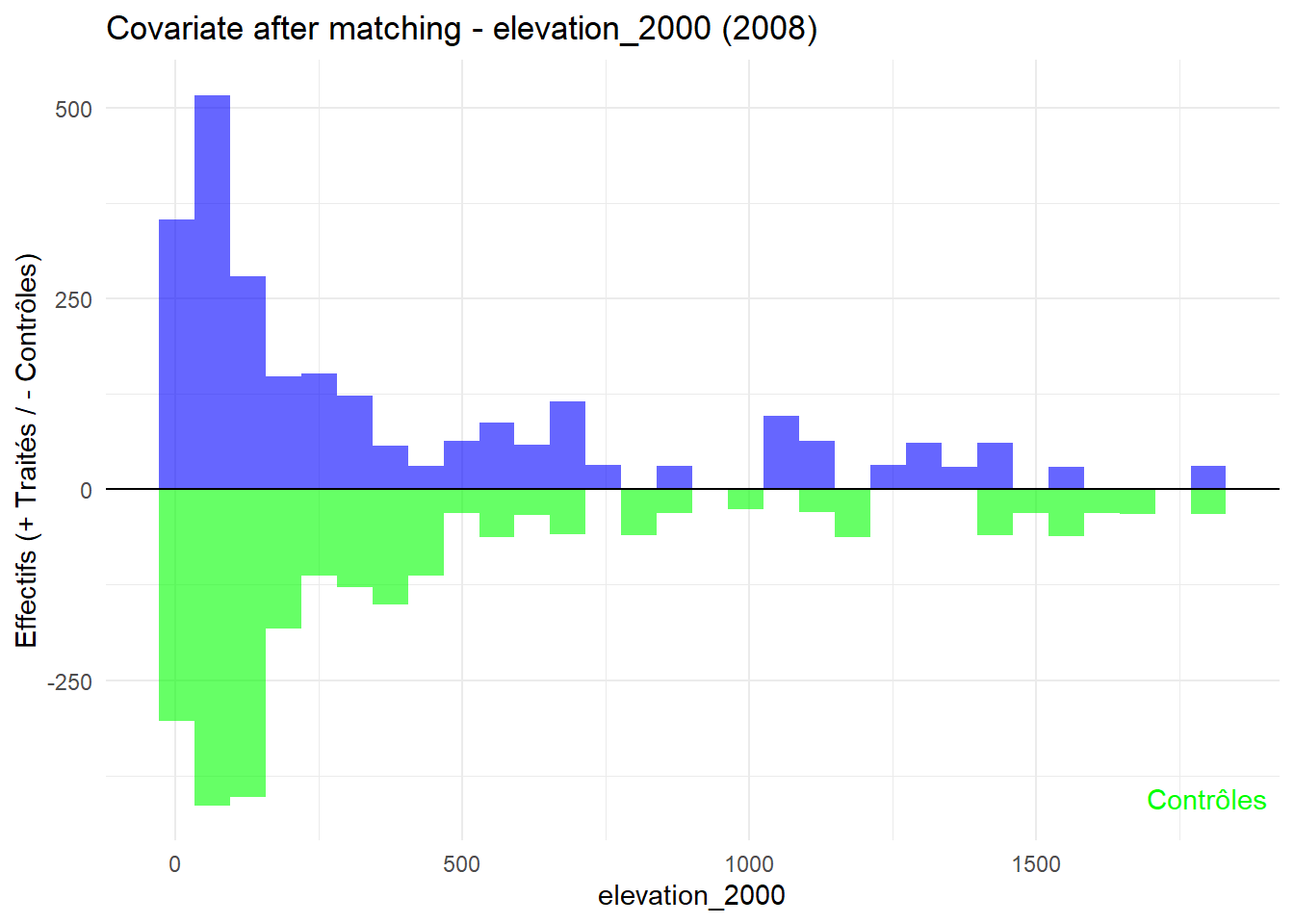
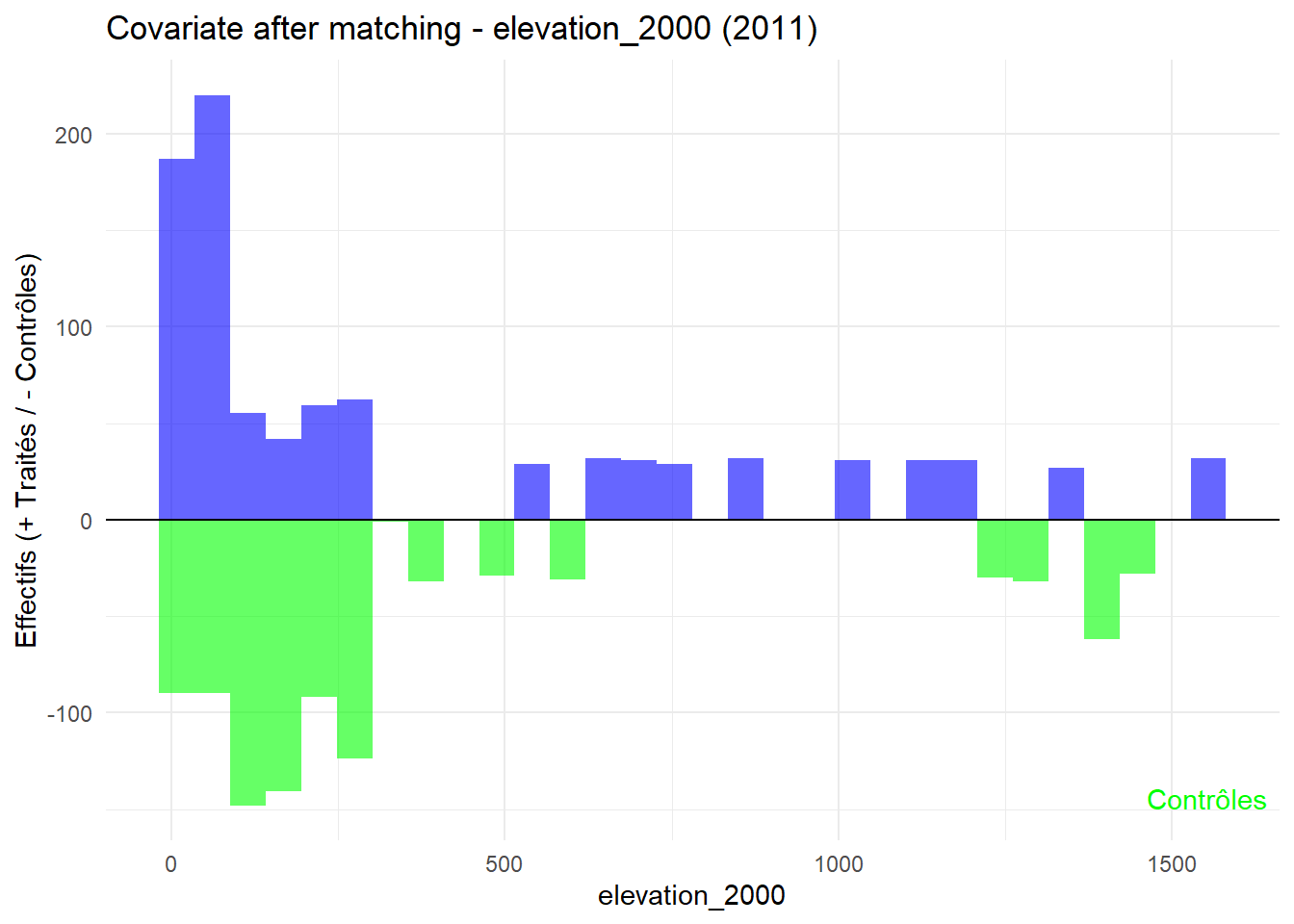
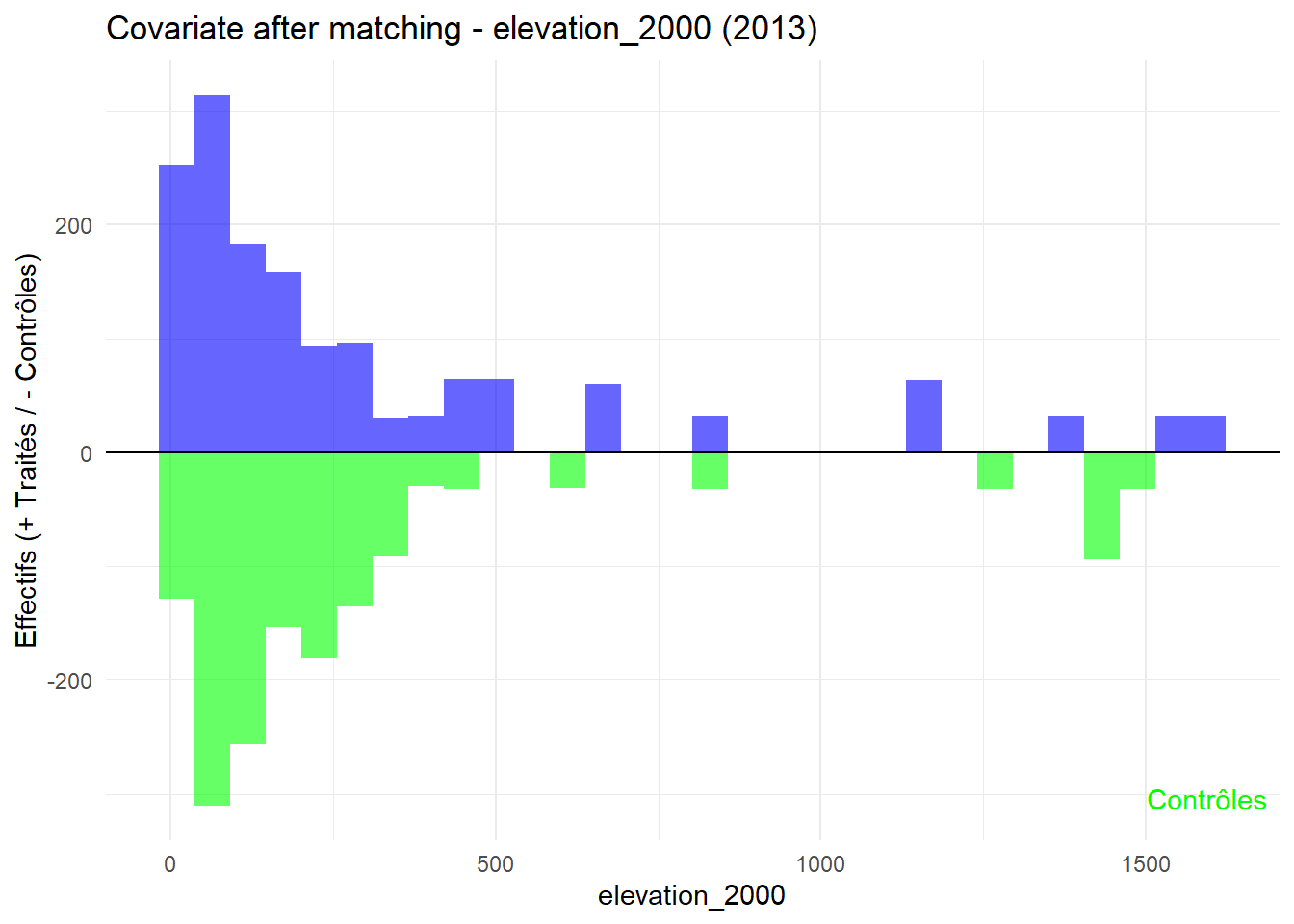
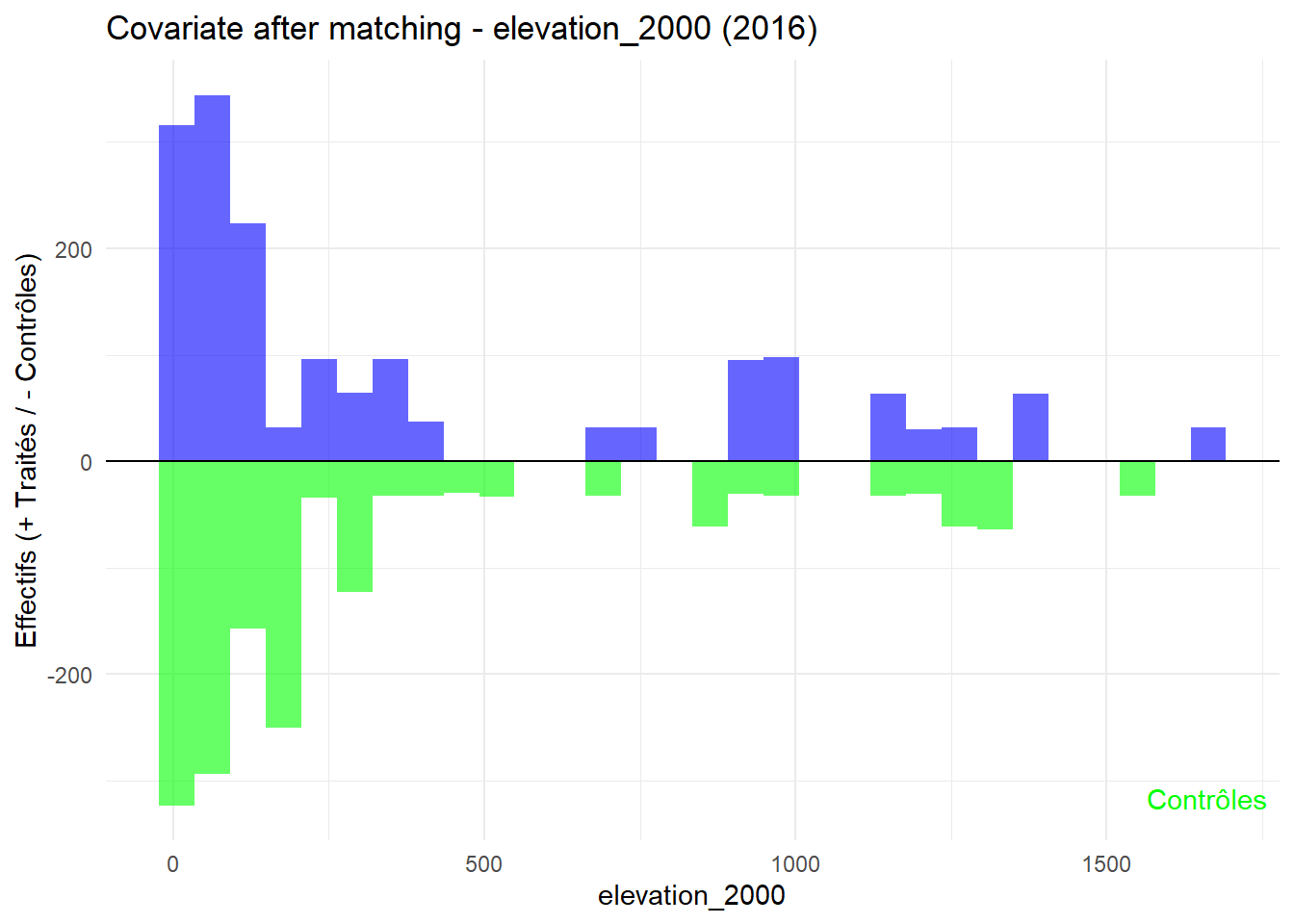
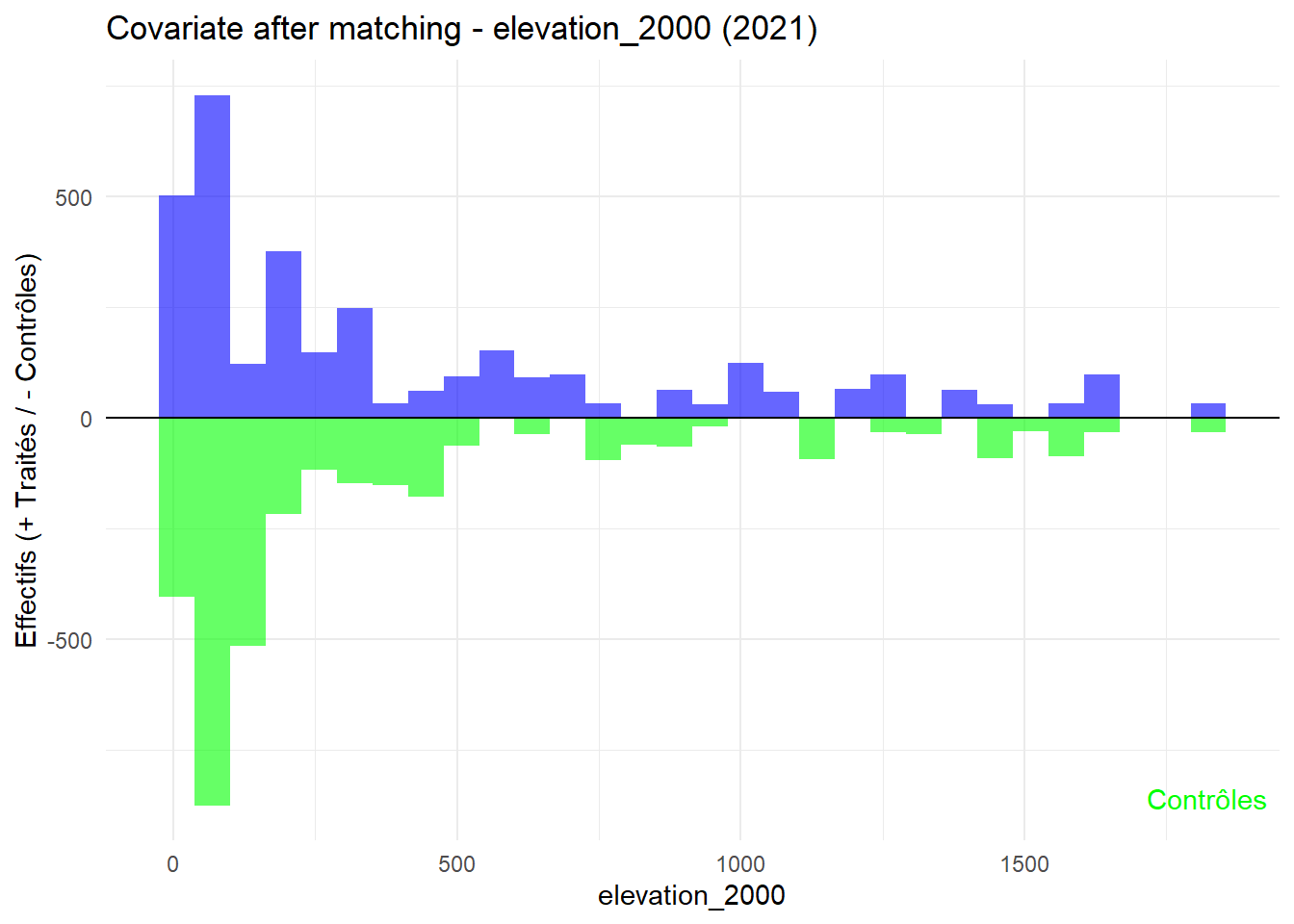
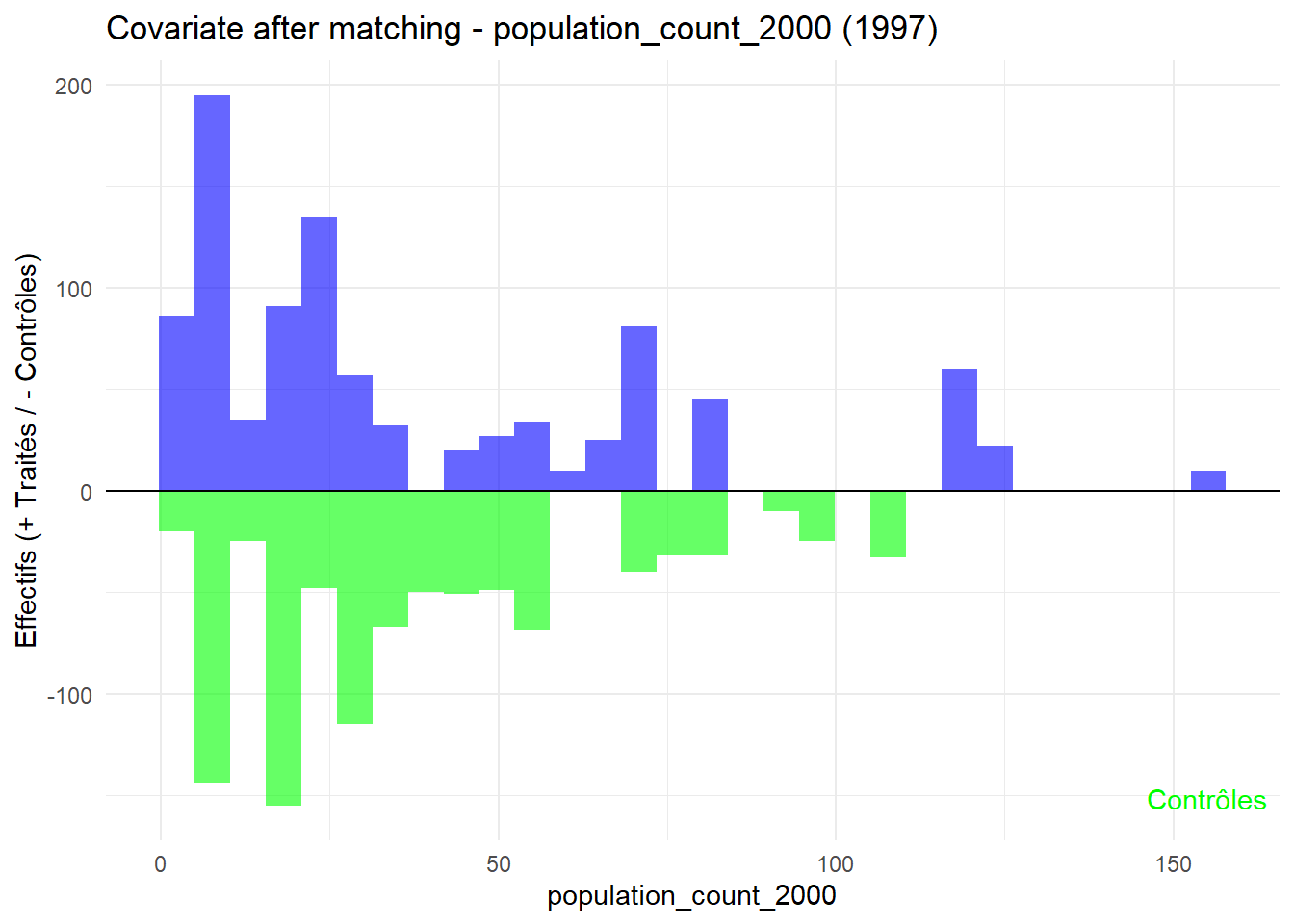
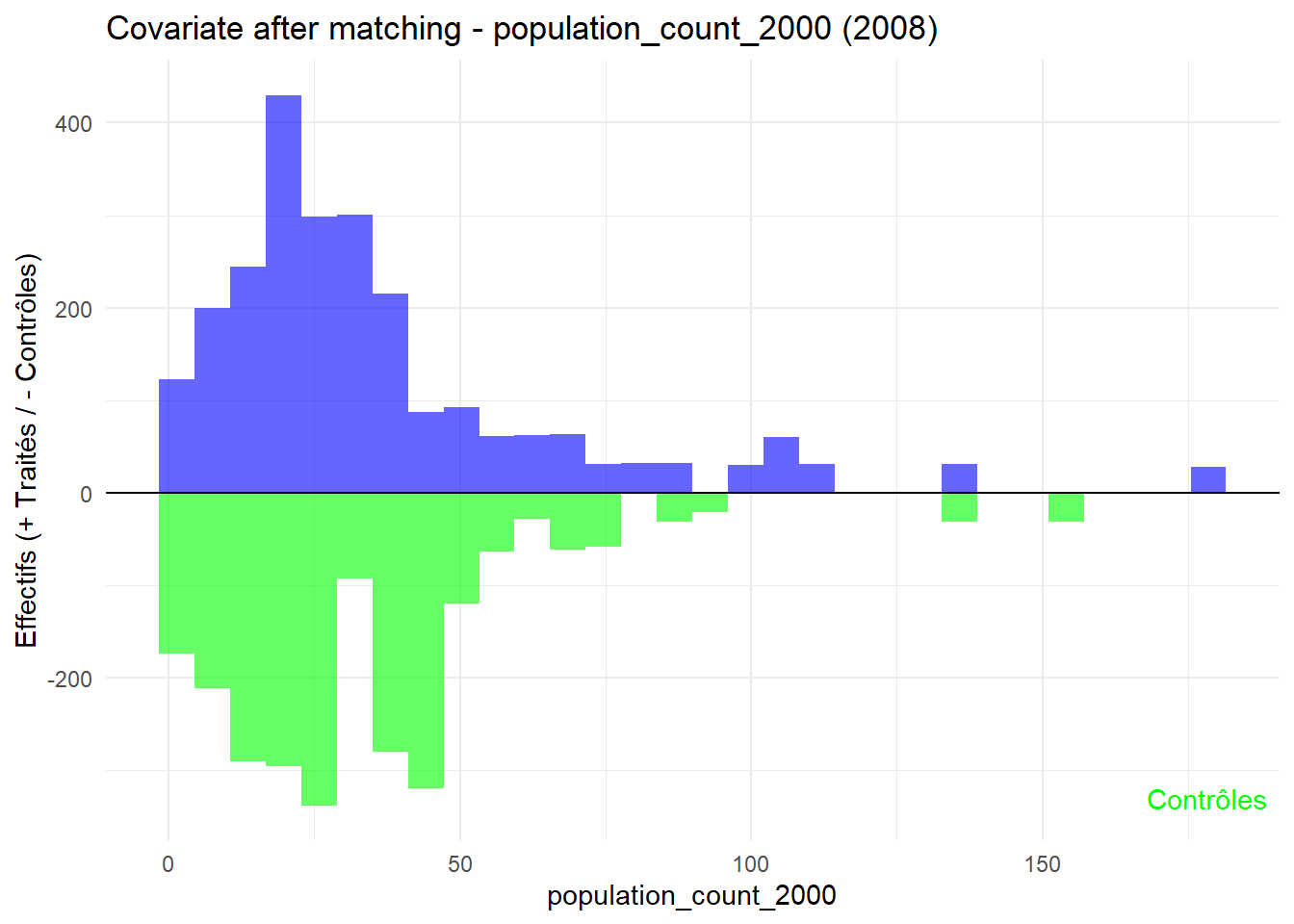
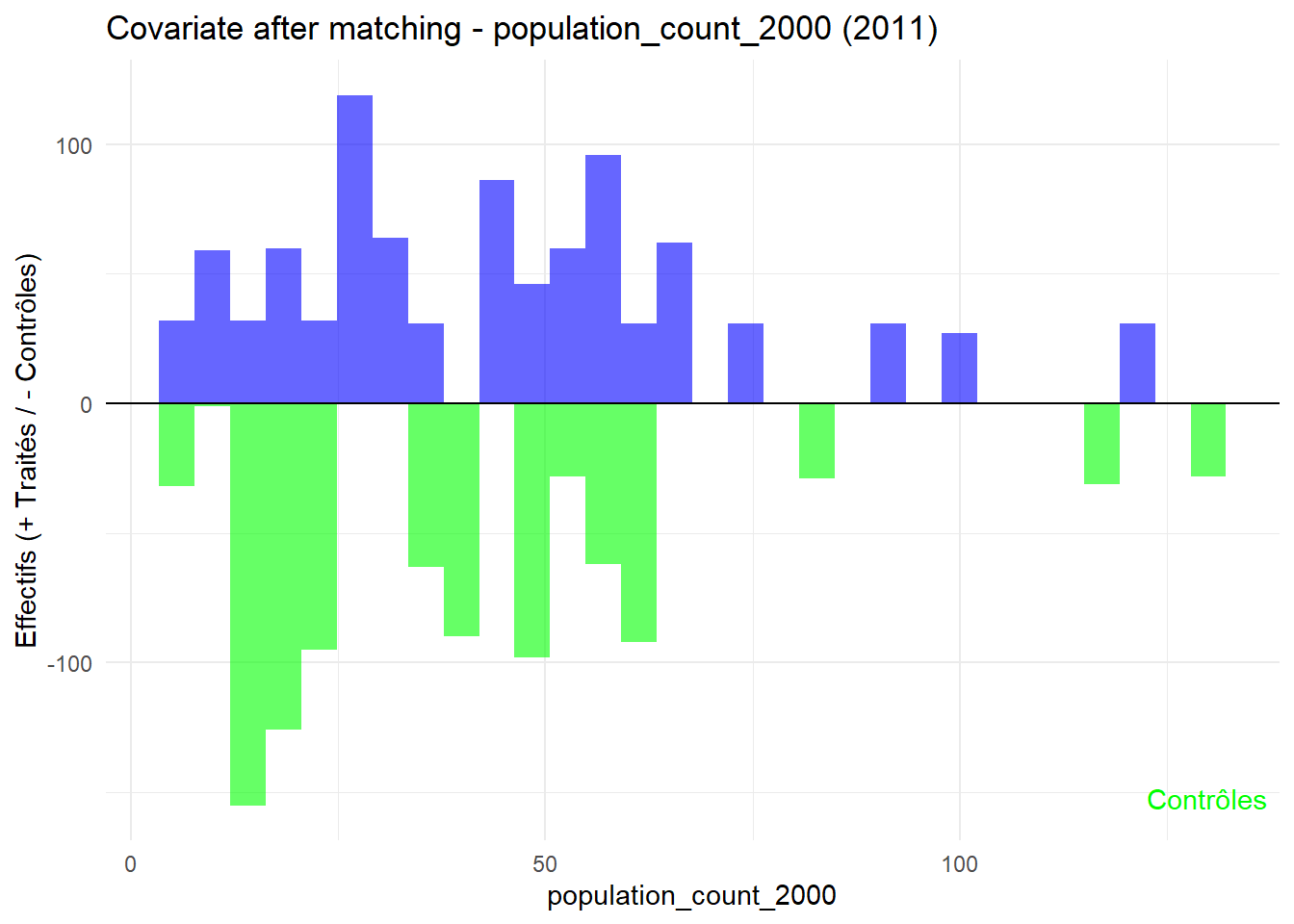
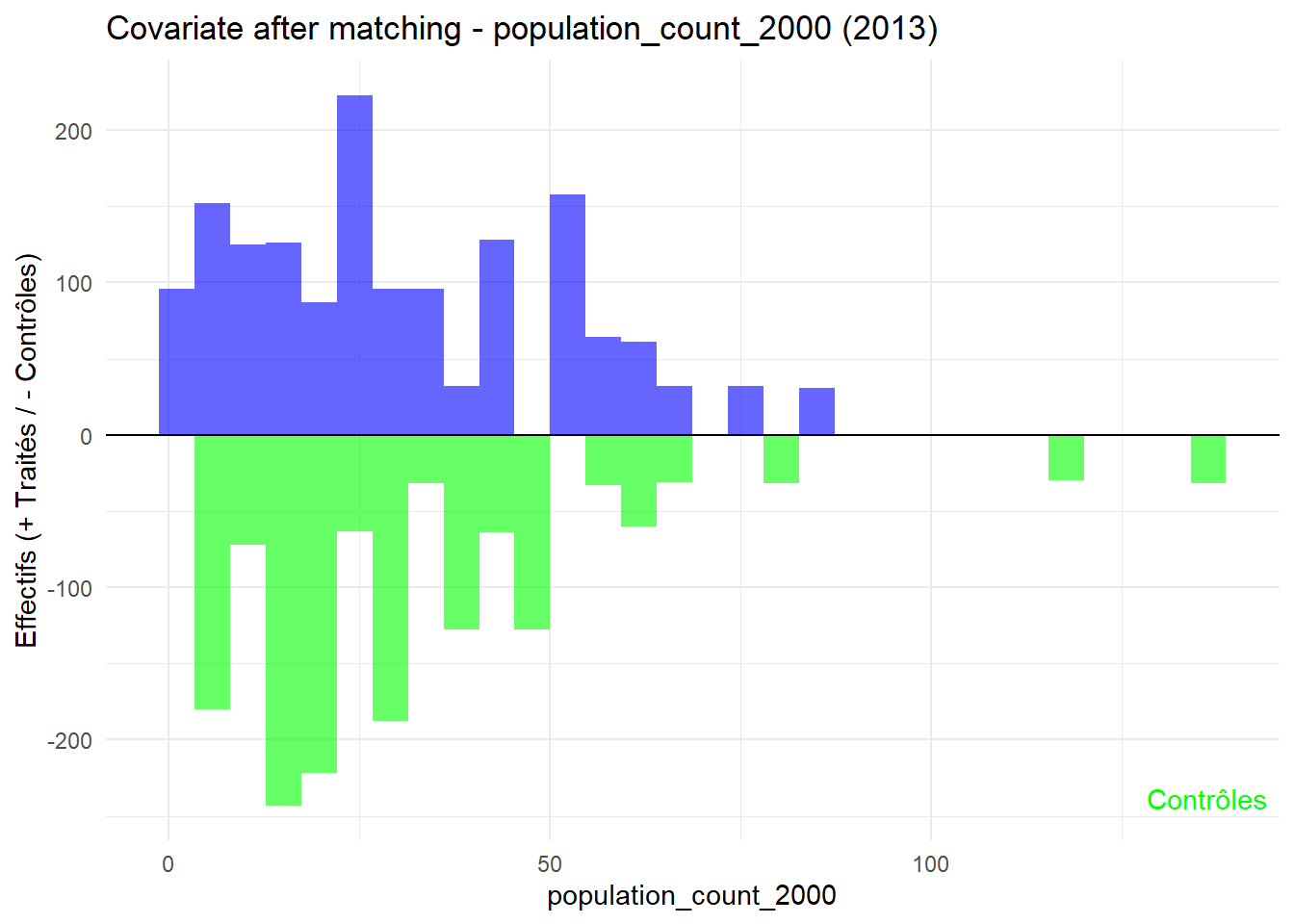
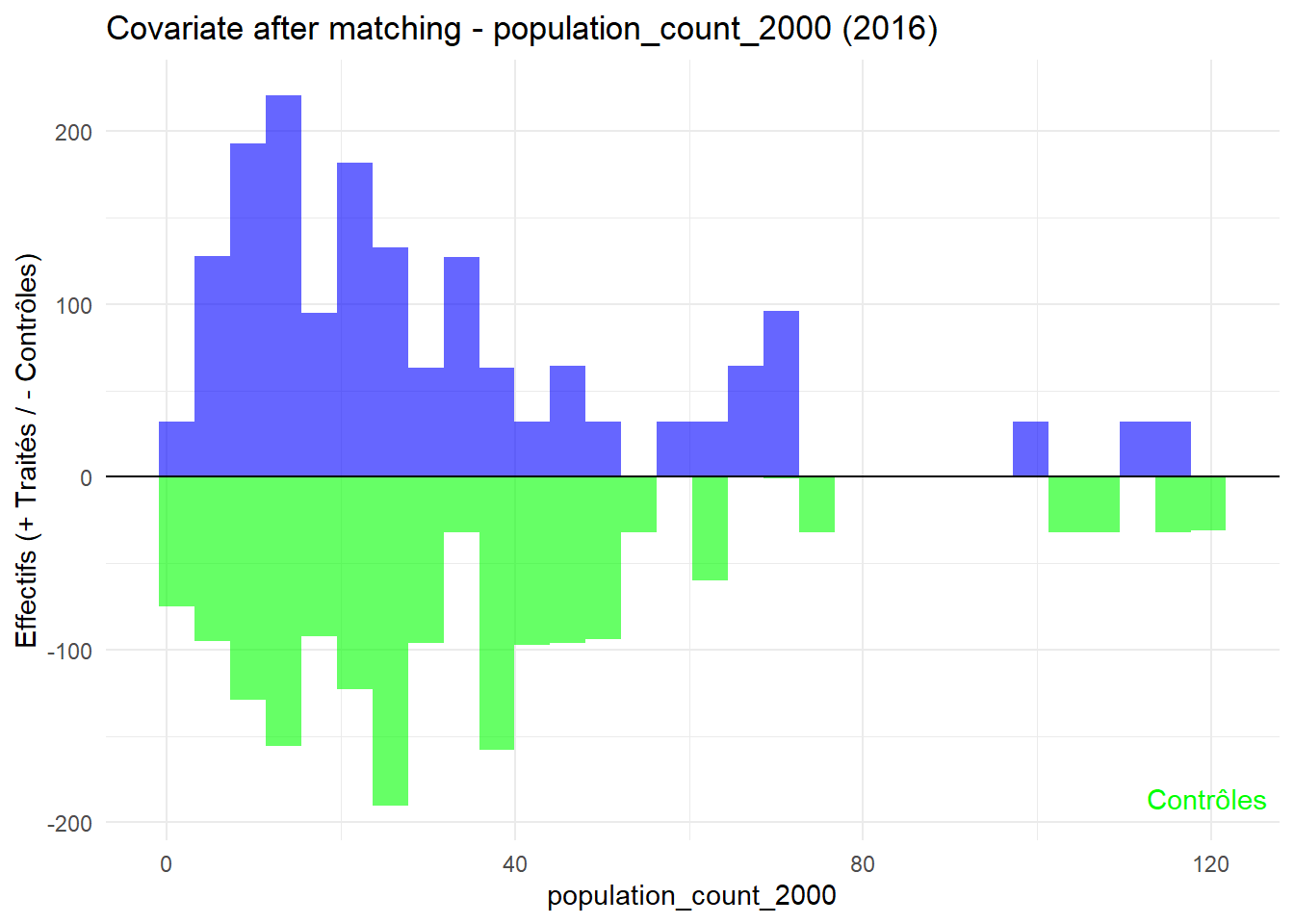
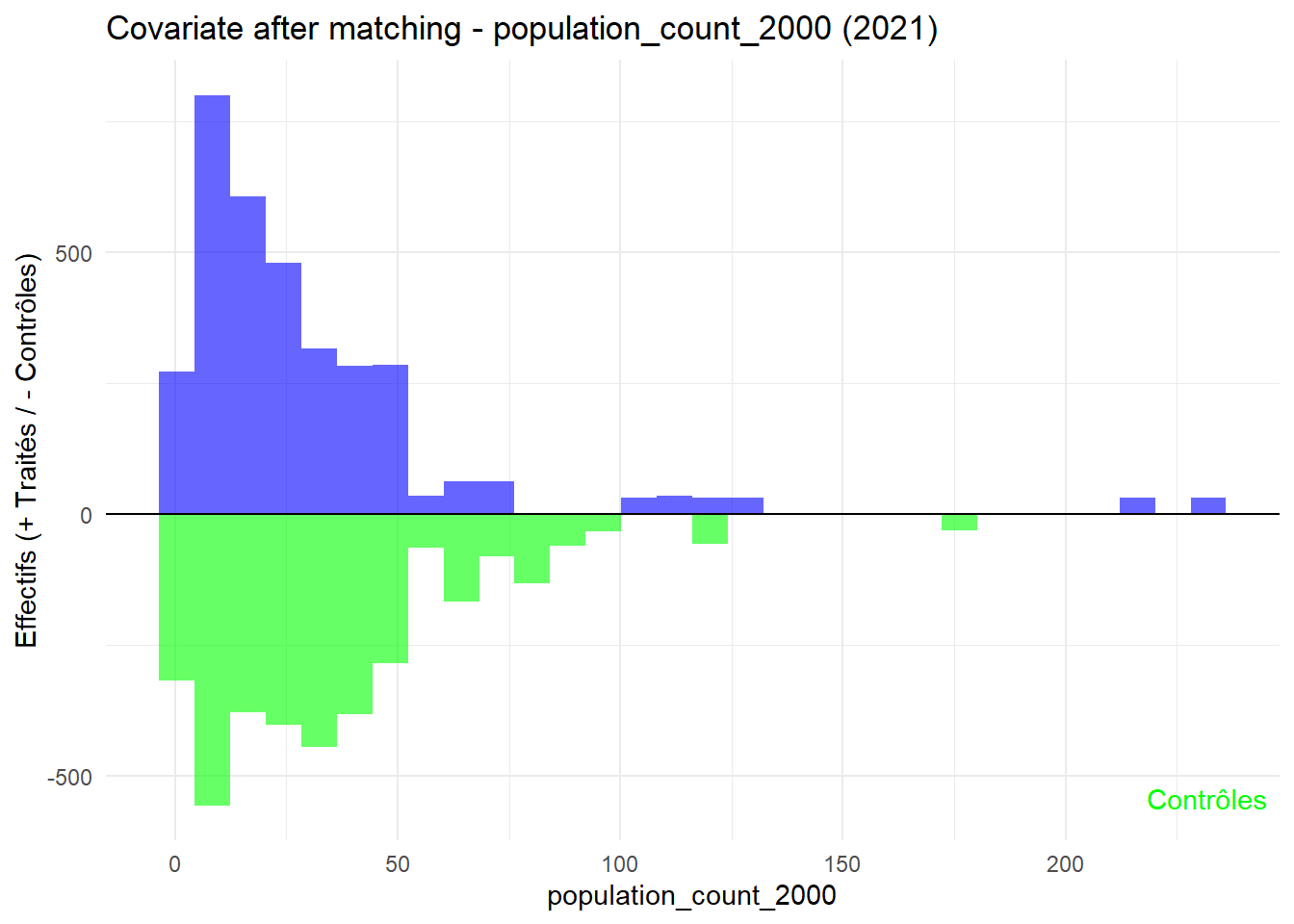
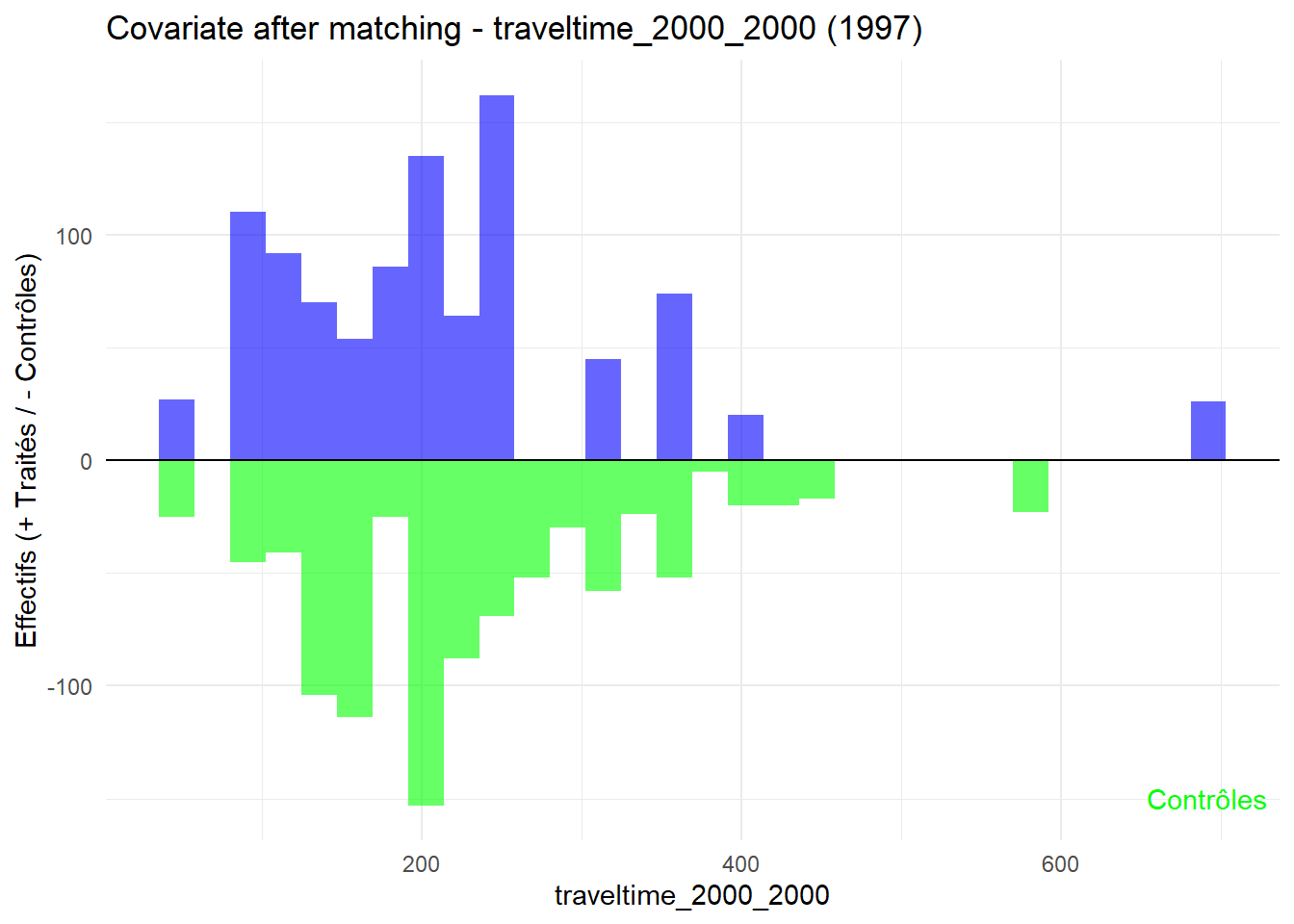
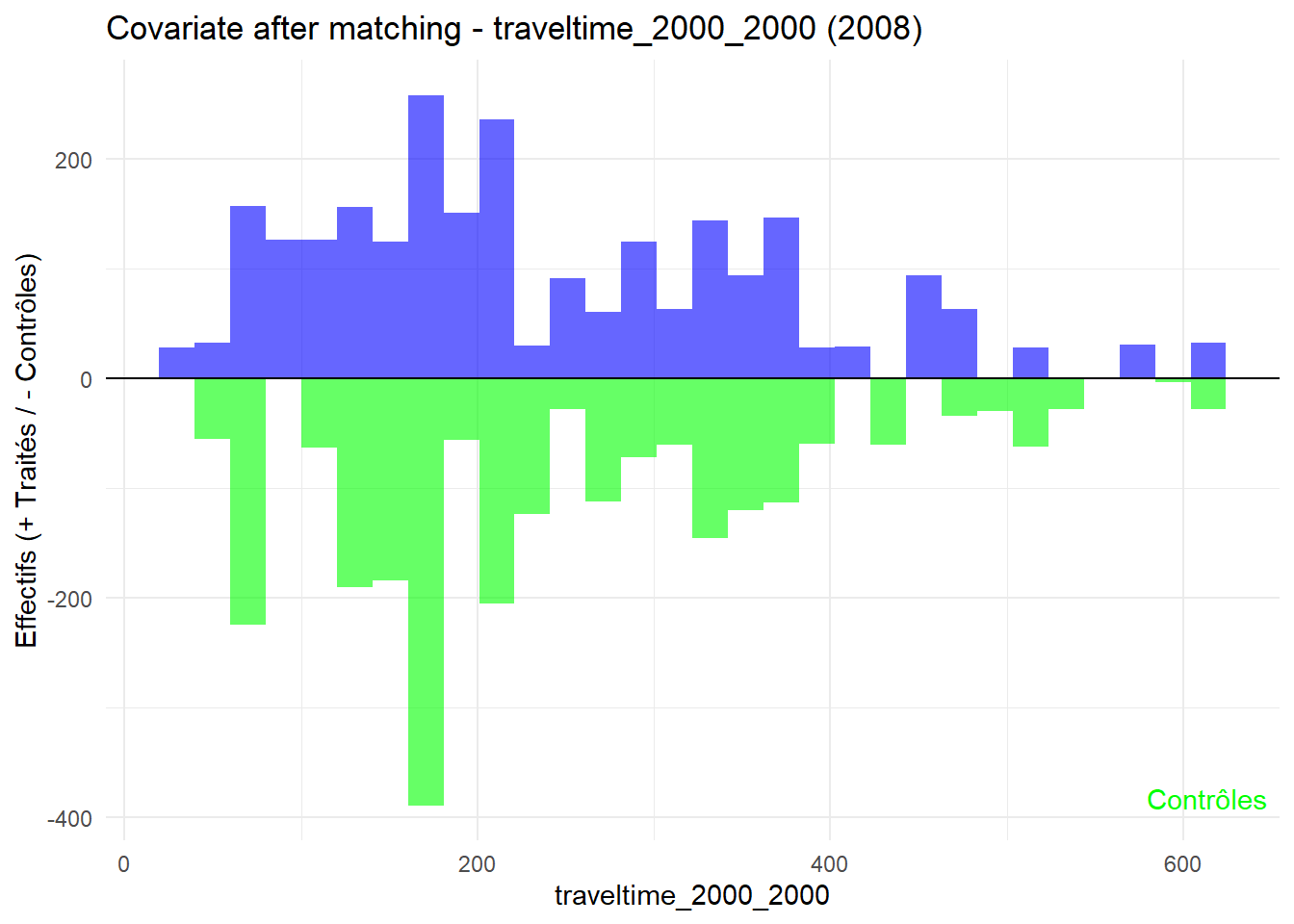
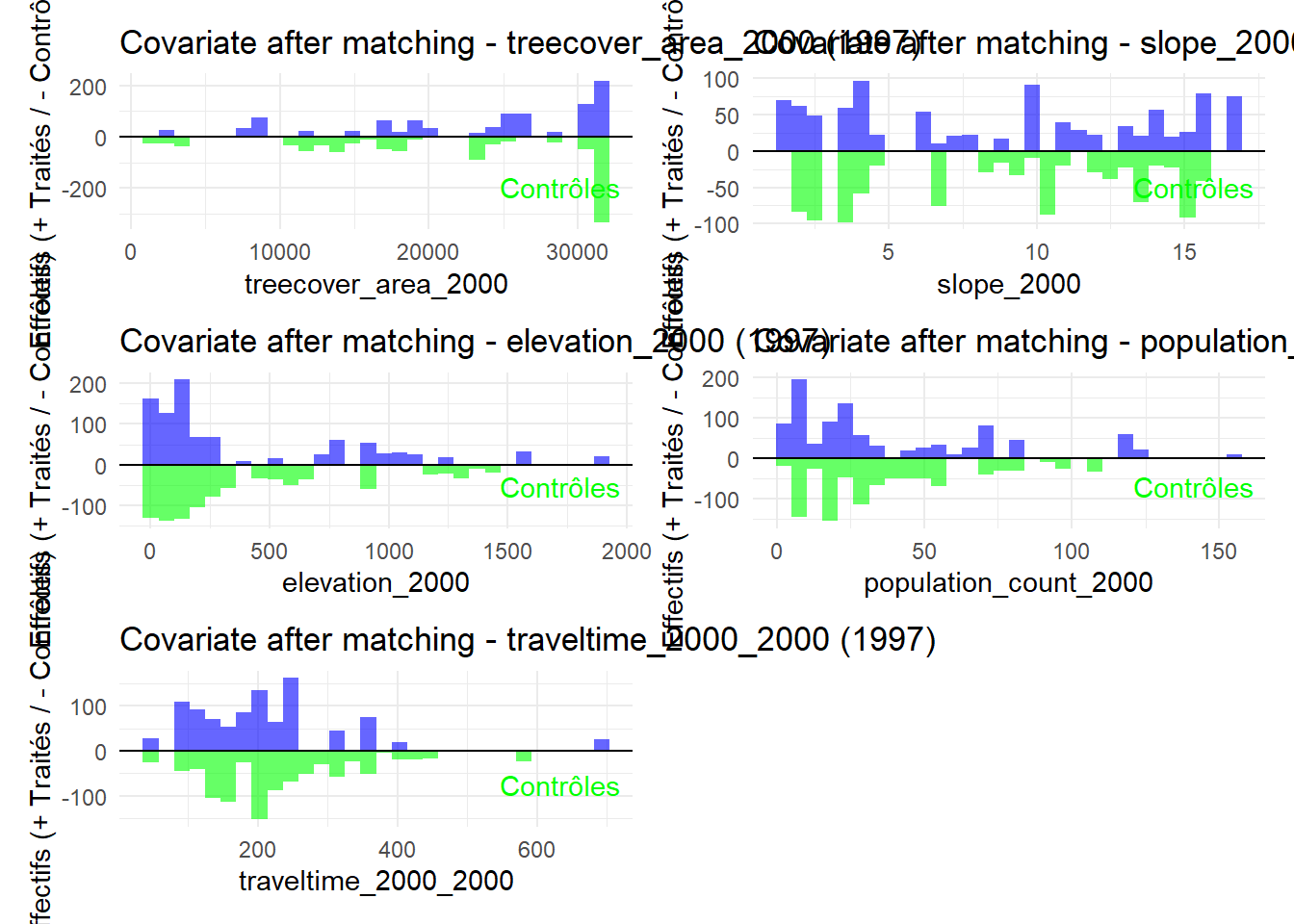
8.3.0.3 Balance test after matching: Histogram
Code
plot_mirror_hist <-function(year, variable){ df <-readRDS(glue("data/derived/data_matched_{year}.rds")) %>%filter(GROUP %in%c("Treatment", "Control")) %>%mutate(treatment =ifelse(GROUP =="Treatment", "Traité", "Contrôle"), value = .data[[variable]] ) treated <- df %>%filter(treatment =="Traité") control <- df %>%filter(treatment =="Contrôle")ggplot() +geom_histogram(data = treated, aes(x = value), bins =30, fill ="blue", alpha =0.6 ) +geom_histogram(data = control, aes(x = value, y =-after_stat(count)),bins =30, fill ="green", alpha =0.6 ) +labs(title =glue("Covariate after matching - {variable} ({year})"),x = variable, y ="Effectifs (+ Traités / - Contrôles)" ) +geom_hline(yintercept =0, color ="black") +annotate("text", x =Inf, y =-Inf, label ="Traités", hjust =1.1, vjust =2, color ="blue") +annotate("text", x =Inf, y =-Inf, label ="Contrôles", hjust =1.1, vjust =-1.5, color ="green") +theme_minimal()}plot_mirror_hist(1997,"treecover_area_2000")
Code
plot_mirror_hist(2008,"treecover_area_2000")
Code
plot_mirror_hist(2011,"treecover_area_2000")
Code
plot_mirror_hist(2013,"treecover_area_2000")
Code
plot_mirror_hist(2016,"treecover_area_2000")
Code
plot_mirror_hist(2021,"treecover_area_2000")
Code
plot_mirror_hist(1997,"slope_2000")
Code
plot_mirror_hist(2008,"slope_2000")
Code
plot_mirror_hist(2011,"slope_2000")
Code
plot_mirror_hist(2013,"slope_2000")
Code
plot_mirror_hist(2016,"slope_2000")
Code
plot_mirror_hist(2021,"slope_2000")
Code
plot_mirror_hist(1997,"elevation_2000")
Code
plot_mirror_hist(2008,"elevation_2000")
Code
plot_mirror_hist(2011,"elevation_2000")
Code
plot_mirror_hist(2013,"elevation_2000")
Code
plot_mirror_hist(2016,"elevation_2000")
Code
plot_mirror_hist(2021,"elevation_2000")
Code
plot_mirror_hist(1997,"population_count_2000")
Code
plot_mirror_hist(2008,"population_count_2000")
Code
plot_mirror_hist(2011,"population_count_2000")
Code
plot_mirror_hist(2013,"population_count_2000")
Code
plot_mirror_hist(2016,"population_count_2000")
Code
plot_mirror_hist(2021,"population_count_2000")
Code
plot_mirror_hist(1997,"traveltime_2000_2000")
Code
plot_mirror_hist(2008,"traveltime_2000_2000")
Code
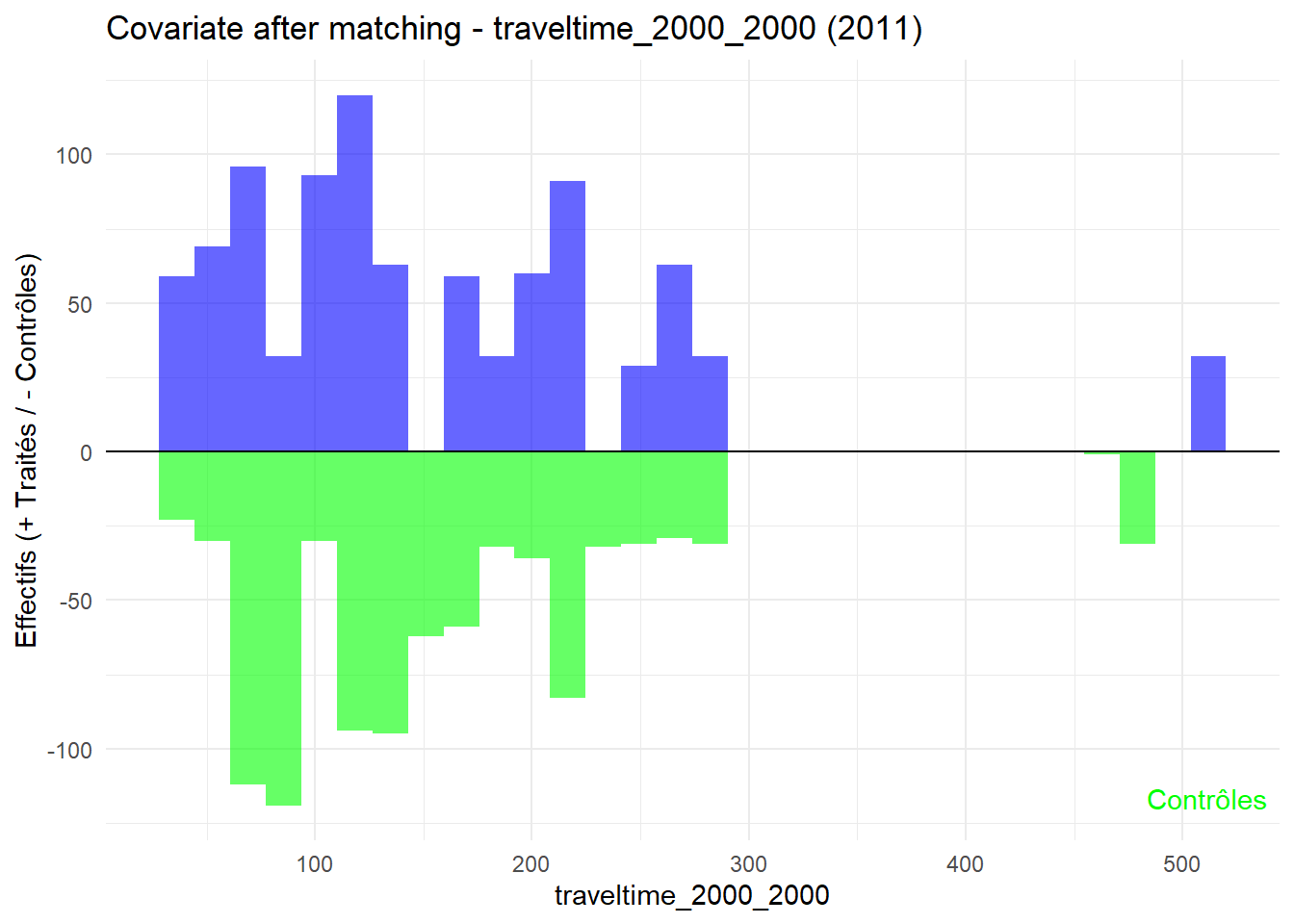
plot_mirror_hist(2011,"traveltime_2000_2000")
Code
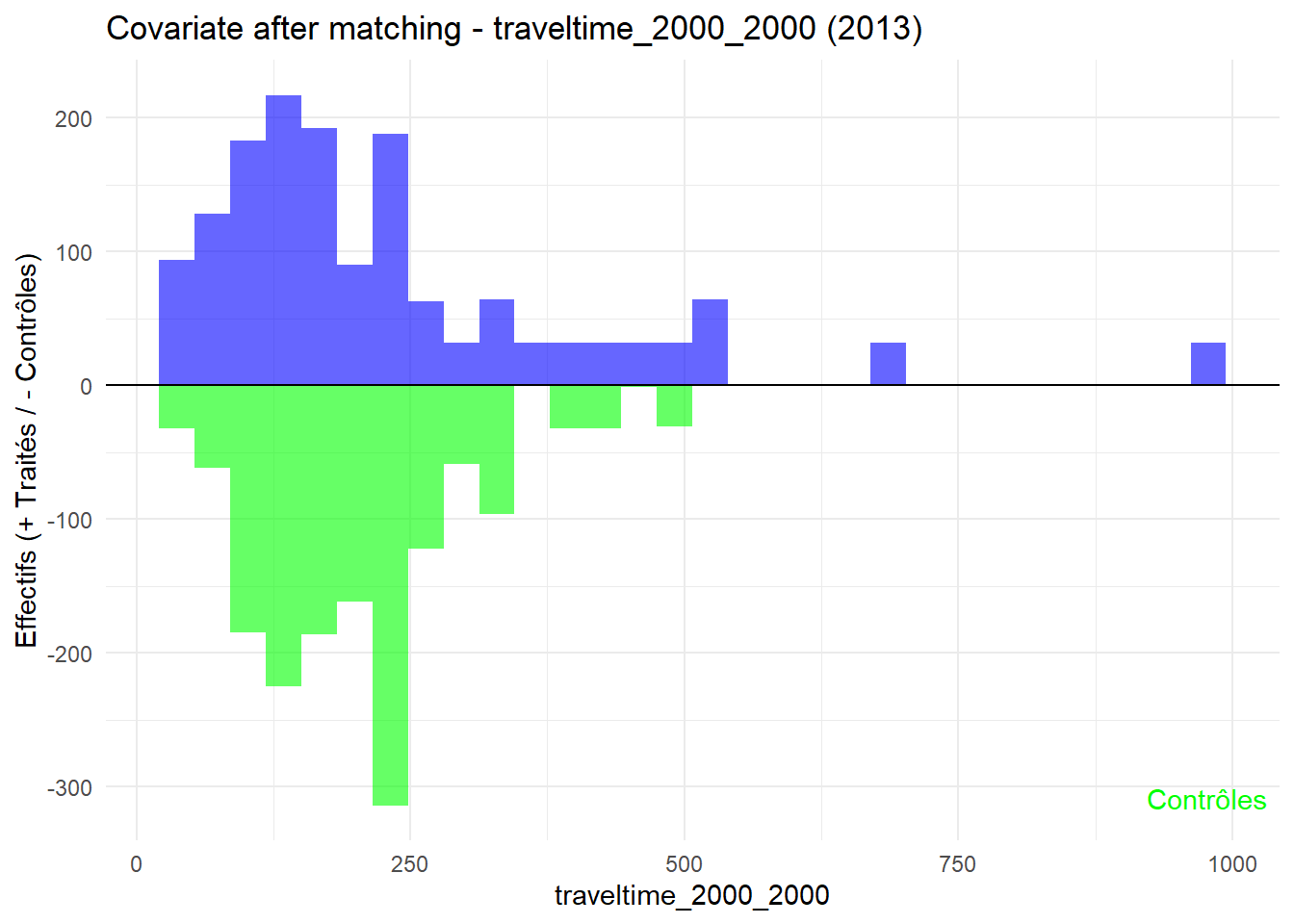
plot_mirror_hist(2013,"traveltime_2000_2000")
Code
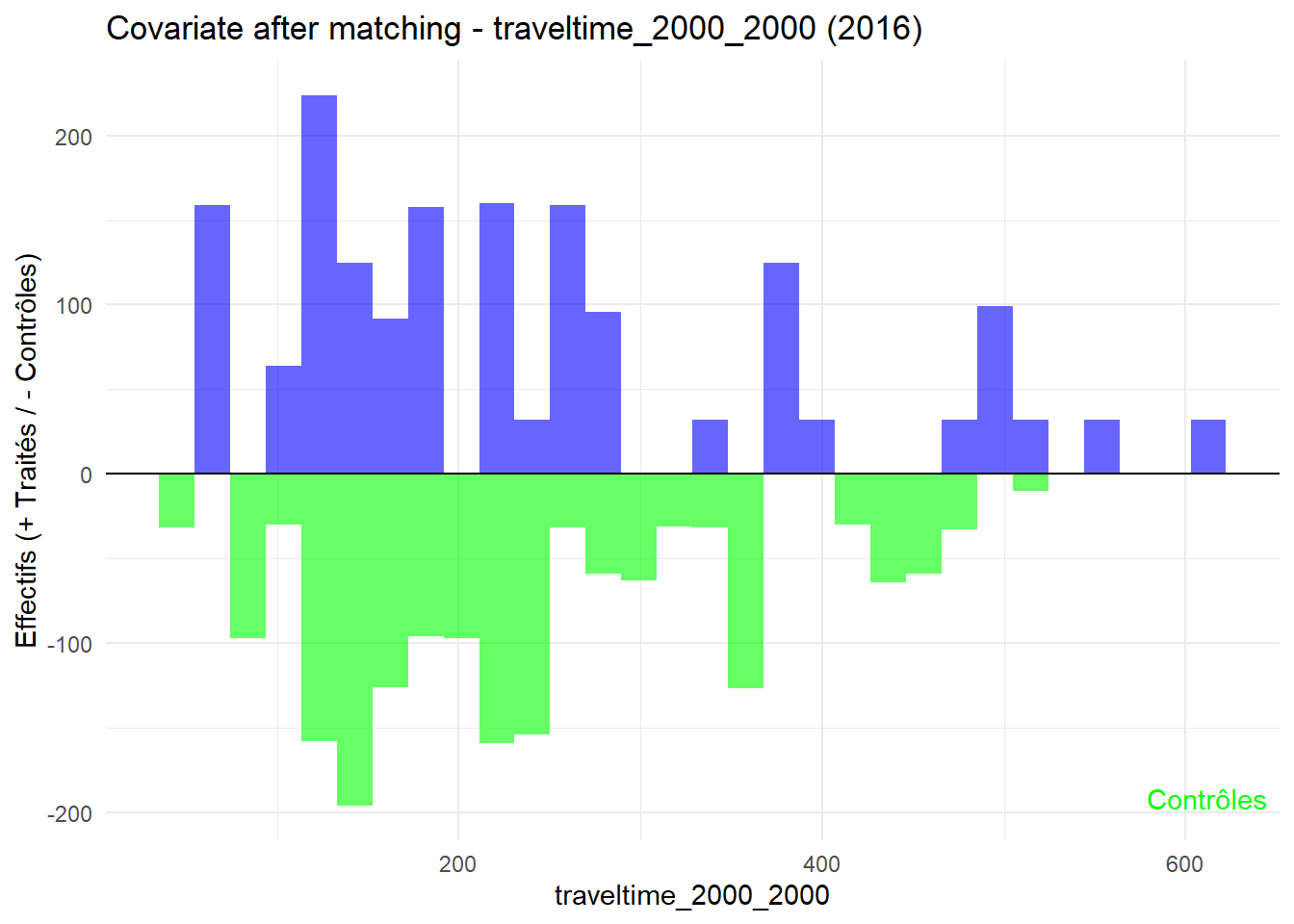
plot_mirror_hist(2016,"traveltime_2000_2000")
Code
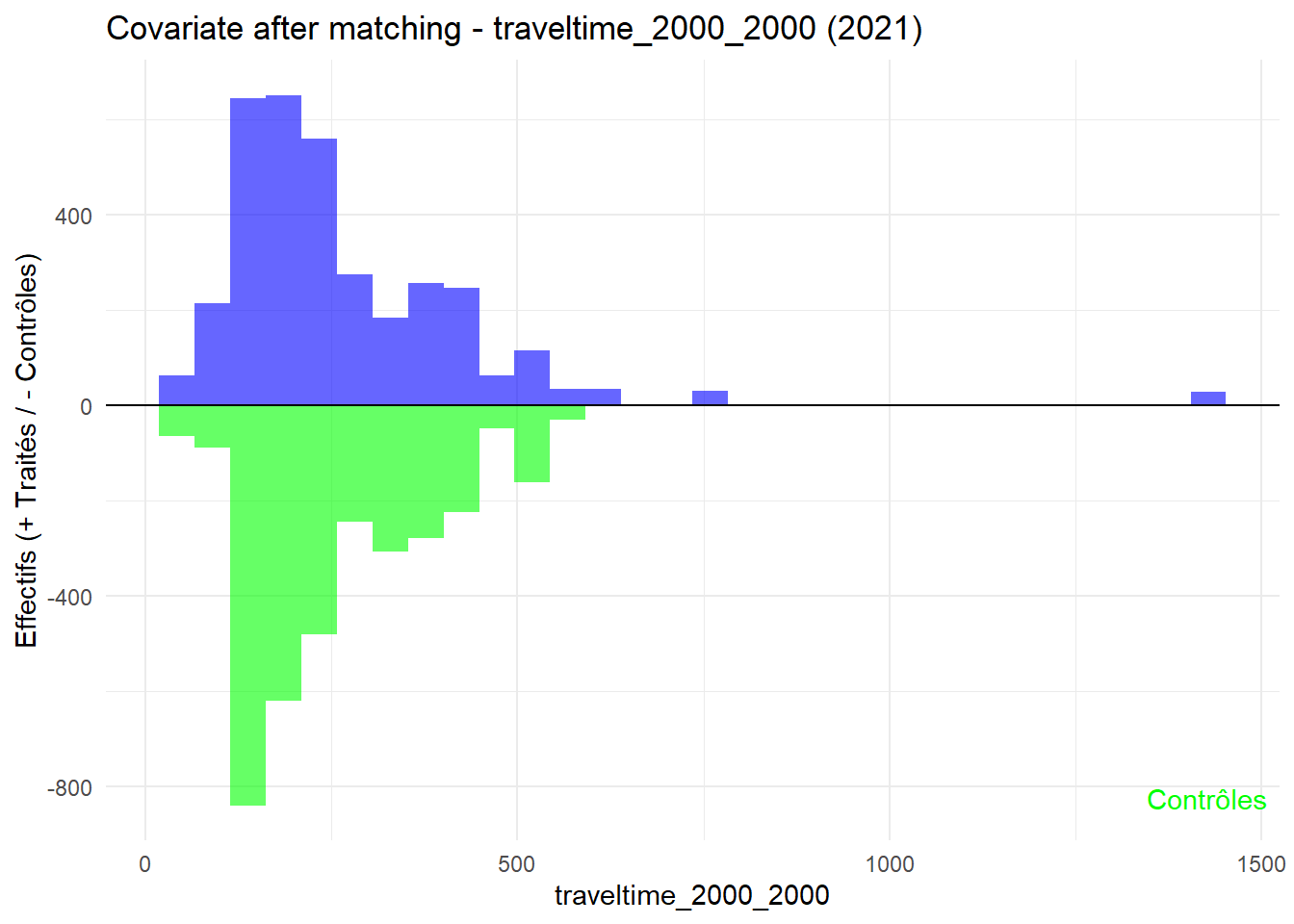
plot_mirror_hist(2021,"traveltime_2000_2000")
Code
plots <-list()for (y inc(1997, 2008, 2011, 2013, 2016, 2021)) {for (v in matching_variables) { plots[[paste0(v, "_", y)]] <-plot_mirror_hist(y, v) }}library(patchwork)# Tous les graphiques pour une année donnéewrap_plots(plots[grep("_1997$", names(plots))], ncol =2)
Code
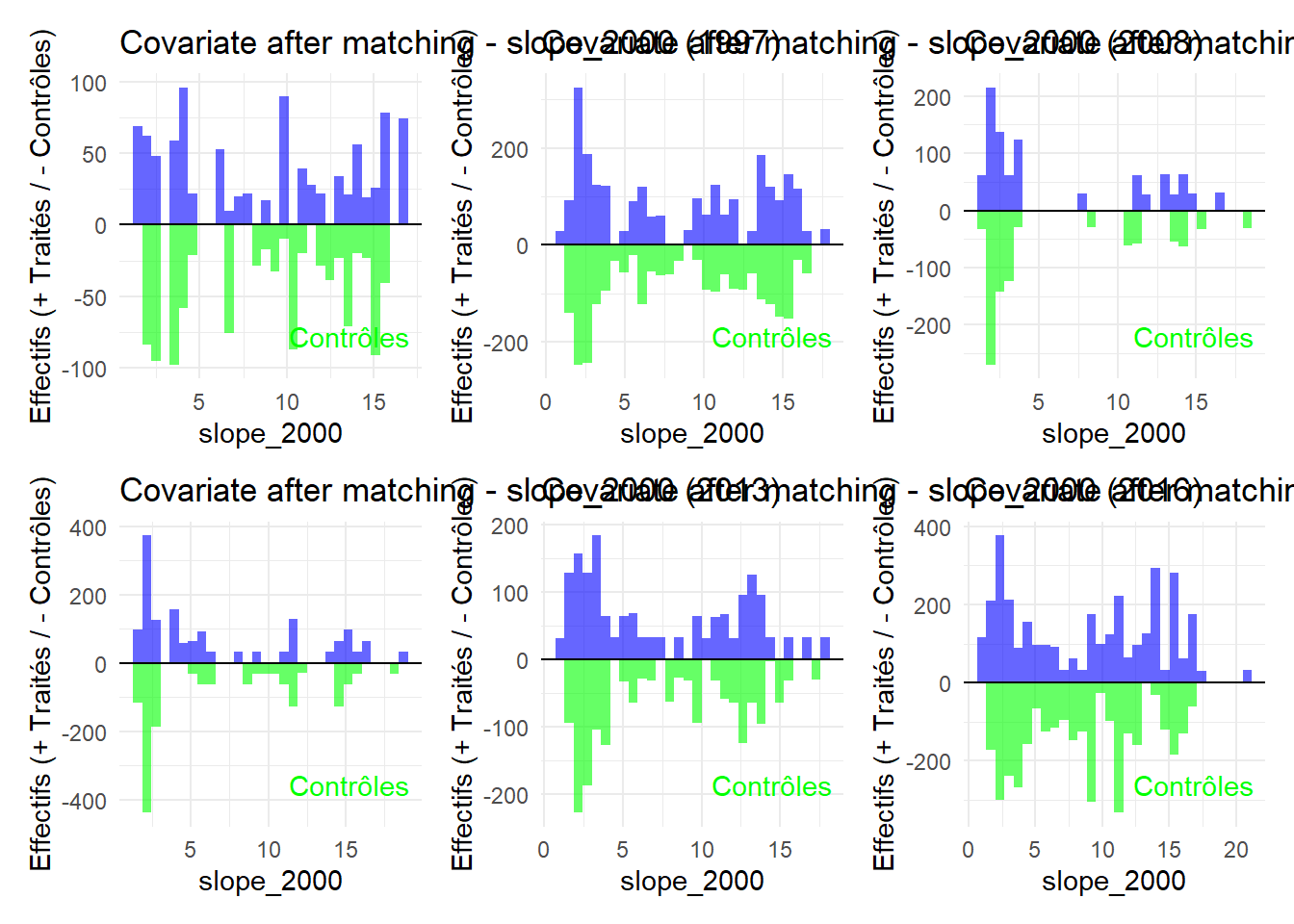
# Tous les graphiques pour une variable donnéewrap_plots(plots[grep("^slope_2000", names(plots))], ncol =3)
L’histogramme compare les moyennes des variables de contrôle après le matching entre les groupes de traitement (en bleu) et de contrôle (en vert) pour chaque année.
Austin, Peter C. 2009. “Balance Diagnostics for Comparing the Distribution of Baseline Covariates Between Treatment Groups in Propensity-Score Matched Samples.”Statistics in Medicine 28 (25): 30833107. https://doi.org/10.1002/sim.3697.
Diamond, Alexis, and Jasjeet S. Sekhon. 2013. “Genetic Matching for Estimating Causal Effects: A General Multivariate Matching Method for Achieving Balance in Observational Studies.”Review of Economics and Statistics 95 (3): 932945. https://doi.org/10.1162/REST_a_00318.
Ho, Daniel E., Kosuke Imai, Gary King, and Elizabeth A. Stuart. 2007. “Matching as Nonparametric Preprocessing for Reducing Model Dependence in Parametric Causal Inference.”Political Analysis 15 (3): 199236. https://doi.org/10.1093/pan/mpl013.