Pour commencer, on récupère le travail réalisé par Carvalho et al. (2020) qui complète les informations physiques de Goodman et al. (2018) avec des données relatives au couvert forestier en 1996, 2006 et 2016 et la diversité d’espèces présentes.
Code
library(tidyverse)library(readxl)library(sf)library(wdpar)library(mapme.biodiversity)# Voir le chapitre "Fondamentaux R" pour une aide à l'import.sup2 <-read_xlsx("data/Carvalho2018sup2.xlsx", # Enplacement du fichierskip =8, # Premières lignes du tableau excel à ne pas liren_max =101, # on ne lit pas les dernières lignes (notes)col_types =c("text", "text", "text", "text", "numeric", "numeric", "numeric", "numeric", "numeric", "numeric", "numeric", "numeric", "numeric", "numeric"))sup4 <-read_xlsx("data/Carvalho2018sup4.xlsx", skip =6,col_types =c("text", "numeric", "text", "numeric", "numeric", "numeric", "numeric", "numeric", "numeric", "numeric"))# Carvalho et al. 2008 document in their supp. material 2: "The three parcels that made up# Andohahela (Parcels I, II and III) comprised different types of dominant vegetation and# associated animal species, and were exposed to distinct pressures. Andohahela was analysed# in its entirety (site number 57), as well as separated"sup2 <- sup2 %>%mutate(PA =recode(PA, `Andohahela complete`="Andohahela"),num_atlas_ =as.integer(`Site number`))sup4 <- sup4 %>%filter(`Habitat type`=="TOTAL") %>%mutate(num_atlas_ =as.numeric(Parcel))load("data/ch2_AP_Vahatra.rds")AP_Vahatra <- AP_Vahatra %>%left_join(sup2, by ="num_atlas_") %>%relocate(PA, .after = nom) %>%left_join(sup4, by ="num_atlas_")
On complète cette information avec des données de couvert forestier.
3.2 Mapme (exemple GFC)
La procédure de traitement de ces fichiers sur Mapme est analogue à celle employée dans la section ?sec-caracteristiques.
Code
# On charge les polygones travaillés au chapitre 1WDPA_Mada <-wdpa_read("data/WDPA/WDPA_Oct2022_MDG-shapefile.zip") # On charge aussi le contour de Madagascarload("data/contour_mada.rds")# On charge les polygones travaillés au chapitre 1WDPA_poly <- WDPA_Mada %>%# On enlève les AP pour lesquelles on n'a que des pointsfilter(st_geometry_type(.) =="MULTIPOLYGON") %>%st_cast("POLYGON")WDPA_poly <-init_portfolio(WDPA_poly,years =2000:2020,outdir ="out",cores =18,add_resources =TRUE)# Get GFW dataWDPA_poly <-get_resources(x = WDPA_poly , resources =c("gfw_treecover", "gfw_lossyear"))# Indicateurs de couvert forestierWDPA_poly <-calc_indicators(x = WDPA_poly,indicators ="treecover_area", min_cover =10, min_size =1)deforest_par_an <- WDPA_poly %>%unnest(treecover_area) %>%# filter(!is.na(years)) %>%pivot_wider(names_from ="years", values_from ="treecover", names_prefix ="treecover_") %>%st_drop_geometry() %>%select(-assetid) %>%group_by(across(WDPAID:CONS_OBJ)) %>%summarise(across(starts_with("treecover"), sum, na.rm =TRUE))# Stats pour AP_Vahatra ------------------------------------# On charge les polygones travaillés au chapitre 2load("data/ch2_AP_Vahatra.rds")APV_poly <-AP_Vahatra %>%# On enlève les AP pour lesquelles on n'a que des pointsfilter(st_geometry_type(.) =="MULTIPOLYGON") %>%st_make_valid() %>%st_cast("POLYGON") %>%st_make_valid()APV_poly <-init_portfolio(APV_poly,years =2000:2020,outdir ="out_Vahatra",cores =18,add_resources =TRUE)# Get GFW dataAPV_poly <-get_resources(x = APV_poly , resources =c("gfw_treecover", "gfw_lossyear"))# Indicateurs de couvert forestierAPV_poly <-calc_indicators(x = APV_poly,indicators ="treecover_area", min_cover =10, min_size =1)APV_par_aire <- APV_poly %>%unnest(treecover_area) %>%# filter(!is.na(years)) %>%pivot_wider(names_from ="years", values_from ="treecover", names_prefix ="treecover_") %>%st_drop_geometry() %>%select(-assetid) %>%group_by(across(!starts_with("treecover"))) %>%summarise(across(starts_with("treecover"), sum, na.rm =TRUE))# Stats pour Mada --------------------------------------------------------# On charge les polygones travaillés au chapitre 1mada_poly <- contour_mada %>%# On enlève les AP pour lesquelles on n'a que des pointsfilter(st_geometry_type(.) =="MULTIPOLYGON") %>%st_cast("POLYGON")mada_poly <-init_portfolio(mada_poly ,years =2000:2020,outdir ="out_Mada",cores =18,add_resources =TRUE)# Get GFW datamada_poly <-get_resources(x = mada_poly , resources =c("gfw_treecover", "gfw_lossyear"))# Indicateurs de couvert forestiermada_poly <-calc_indicators(x = mada_poly,indicators ="treecover_area", min_cover =10, min_size =1)mada_global <- mada_poly %>%unnest(treecover_area) %>%# filter(!is.na(years)) %>%pivot_wider(names_from ="years", values_from ="treecover", names_prefix ="treecover_") %>%st_drop_geometry() %>%select(-assetid) %>%group_by(across(!starts_with("treecover"))) %>%summarise(across(starts_with("treecover"), sum, na.rm =TRUE))library(writexl)write_xlsx(list(WDPA = deforest_par_an,Vahatra = APV_par_aire, Madagascar = mada_global),path ="couvert_forestier_10_1.xlsx")
Toutefois, en raison d’un problème liés à la gestion des calculs volumineux, les calculs pour certaines aires protégées renvoient des données aberrantes. Ce point sera mis à jour dans ce guide dès la résolution des erreurs rencontrées.
A ce stade on se concentrera donc sur les données de TFM présentées plus bas.
3.3 Google Earth Engine (exemple GFC)
La plateforme Google Earth Engine est un outil particulièrement pratique et performant pour mobiliser et traiter des données satellitaires. Google Earth Engine peut être utilisé :
en interrogeant son API, et notamment :
en python, avec la librairie gee permet d’interroger l’API de Google Earth Engine.
en R, au travers de la librairie rgee. Cette dernière est relativement facile d’usage, mais elle est difficile à configurer. Pour aller plus loin : https://r-earthengine.com/rgeebook/
directement sur la plateforme https://code.earthengine.google.com/
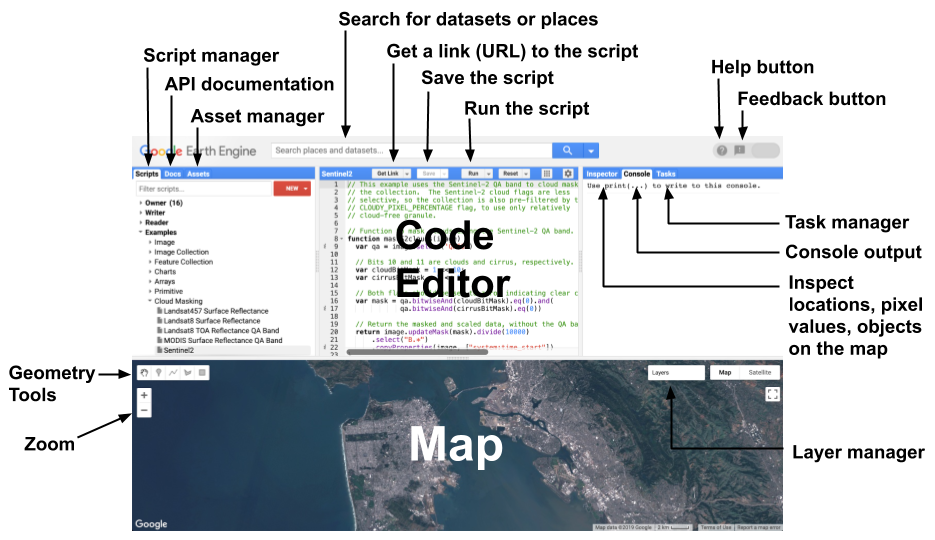
La consolde de codage de Google Earth Engine prend la forme suivante :
Diagramme des composants de la console Google Earth Engine
Le langage utilisé sur cet interface est du Javascript. Ci-dessous un exemple de code qui génère les surface (en hectares) de perte de couvert forestier. Pour fonctionner, ce code doit être collé dans un script sur la plateforme Google Earth Engine lancé en cliquant sur “Run”, puis en cliquant sur “Tasks” pour exécuter le code.
Code
scale =30// PREPARE DATA//look at tree cover, find the areavar treeCover = gfc2021.select(['treecover2000']);var areaCover = treeCover.multiply(ee.Image.pixelArea()).divide(10000).select([0],["areacover"])// total loss areavar loss = gfc2021.select(['loss']);var areaLoss = loss.gt(0).multiply(ee.Image.pixelArea()).divide(10000).select([0],["arealoss"]);// total gain areavar gain = gfc2021.select(['gain'])var areaGain = gain.gt(0).multiply(ee.Image.pixelArea()).divide(10000).select([0],["areagain"]);// final imagevar total = gfc2021.addBands(areaCover).addBands(areaLoss).addBands(areaGain)// TOTAL COVER// Map cover area per featurevar districtSums = areaCover.reduceRegions({collection: testgu,reducer: ee.Reducer.sum(),scale: scale, });var addVar =function(feature) {// function to iterate over the sequence of yearsvar addVarYear =function(year, feat) {// cast var year = ee.Number(year).toInt() feat = ee.Feature(feat)// actual year to write as propertyvar actual_year = ee.Number(2000).add(year)// filter year:// 1st: get maskvar filtered = total.select("lossyear").eq(year)// 2nd: apply mask filtered = total.updateMask(filtered)// reduce variables over the featurevar reduc = filtered.reduceRegion({geometry: feature.geometry(),reducer: ee.Reducer.sum(),scale: scale,maxPixels:1e9 })// get resultsvar loss = ee.Number(reduc.get("arealoss"))var gain = ee.Number(reduc.get("areagain"))// set namesvar nameloss = ee.String("loss_").cat(actual_year)var namegain = ee.String("gain_").cat(actual_year)// set properties to the featurereturn feat.set(nameloss, loss, namegain, gain) }// iterate over the sequencevar newfeat = ee.Feature(years.iterate(addVarYear, feature));// return feature with new propertiesreturn newfeat }// Map over the FeatureCollectionvar areas = districtSums.map(addVar);// Export PA deforestation to a CSV file. Export.table.toDrive({collection: areas,description:'forest_loss_WDPA_Madagascar',fileFormat:'CSV' });
3.4 Python (exemple TMF)
Fichiers préparés en python (code à venir), directement sur les rasters.
Code
# On charge les fichiers préparés par Marc en python (contient 2 feuilles)tableur_tmf <-"data/TMFchangeYear_AP_Vahatra.xlsx"# On commence par charger la feuille déforestationtmf_vahatra_defor <-read_excel(tableur_tmf,sheet ="TMFdeforestationYear") %>%select(nom, starts_with("TMF")) # on ne garde que les variables pertinentes# On fait ensuite de même avec la feuille dégradationtmf_vahatra_degrad <-read_excel(tableur_tmf,sheet ="TMFdegradationYear") %>%select(nom, starts_with("TMF")) # Onn ne garde que les feuilles pertinentesAP_Vahatra <- AP_Vahatra %>%left_join(tmf_vahatra_degrad, by ="nom") %>%left_join(tmf_vahatra_defor, by ="nom") TMF_ratios <- AP_Vahatra %>%st_drop_geometry() %>%select(nom, starts_with("Forest cover"), starts_with("TMF")) %>%pivot_longer(cols =starts_with("TMF"), names_to ="variable", values_to ="surface_ha") %>%mutate(an_valeur =str_extract(variable, "[:digit:]{4}"),an_valeur =as.numeric(an_valeur),surface_ratio =case_when( an_valeur <2000~ surface_ha /`Forest cover (ha) in 2006`, an_valeur >2009~ surface_ha /`Forest cover (ha) in 2016`,TRUE~ surface_ha /`Forest cover (ha) in 2006`),variable =str_replace(variable, "HA", "ratio")) %>%select(nom, variable, surface_ratio) %>%pivot_wider(names_from = variable, values_from = surface_ratio) %>%select(nom, starts_with("TMF"))AP_Vahatra <- AP_Vahatra %>%left_join(TMF_ratios, by ="nom")save(AP_Vahatra, file ="data/ch3_AP_Vahatra.rds")
3.5 Alternatives
Si on n’est pas à l’aise avec les outils mentionnés plus haut, l’outil Geoquery d’AidData permet d’obtenir des statistiques par aire administrative. Il est également possible de formuler des demandes spécifiques pour d’autres polygones que des aires administratives au travers d’un formulaire dédié.
Carvalho, Fabio, Kerry A. Brown, Adam D. Gordon, Gabriel U. Yesuf, Marie Jeanne Raherilalao, Achille P. Raselimanana, Voahangy Soarimalala, and Steven M. Goodman. 2020. “Methods for Prioritizing Protected Areas Using Individual and Aggregate Rankings.”Environmental Conservation 47 (2): 113–22. https://doi.org/10.1017/S0376892920000090.
Goodman, Steven M., Marie Jeanne Raherilalao, Sébastien Wohlhauser, Jean Clarck N. Rabenandrasana, Herivololona M. Rakotondratsimba, Fanja Andriamialisoa, and Malalarisoa Razafimpahanana. 2018. Les Aires Protégées Terrestres de Madagascar: Leur Histoire, Description Et Biote. Association Vahatra.