Pour le cas d’études auquel on s’intéresse, on n’a pas une seule date de mise en oeuvre de l’intervention à évaluer, mais un échelonnement des dates de mises en oeuvre. En d’autres termes, les aires protégées ont été créées à des dates différentes. Pour ce type de cas, on va utiliser une variante de la méthode de différence de doubles différences, qui est dite “échelonnées” (staggered diff-in-diff). Cette méthode a été conceptualisée par Callaway et Sant’Anna (2021b) et ces mêmes auteurs ont programmé mise en oeuvre pour R dans la librairie {did} (Callaway and Sant’Anna 2021a).
10.2 Application aux polygones d’aires protégées
La spécification employée peut se traduire de la manière suivante :
On l’applique aux aires protégées et à leur déforestation entre 1990 et 2021. On commence par préparer le jeu de données tel qu’attendu par {did}, de sorte à obtenir :
Code
library(did) # Pour des doubles-différences échelonnéeslibrary(tidyverse) # Pur faciliter la manipulation de donnéeslibrary(lubridate) # Pour modifier les dateslibrary(gt) # Pour de jolis tableauxload("data/ch3_AP_Vahatra.rds") # On charge les données préparées au chapitre 3options(scipen =999) # On désactive les notations scientifiques# On prépare le jeu de données au format attendu par {did}ap_did <- AP_Vahatra %>%select(nom, date_creation, num_atlas = num_atlas_, starts_with("TMF"),cat_iucn = cat__iucn) %>%mutate(annee_creation =year(date_creation)) %>%pivot_longer(cols =starts_with("TMF"), names_to ="TMF_variable", values_to ="TMF_value") %>%mutate(annee =str_extract(TMF_variable, "[:digit:]{4}"),annee =as.numeric(annee),traitee =ifelse(annee > annee_creation, 1, 0),TMF_variable =str_remove(TMF_variable, "TMF"),TMF_variable =str_remove(TMF_variable, "_[:digit:]{4}"),group =1) %>%pivot_wider(names_from = TMF_variable, values_from = TMF_value)gt(slice(ap_did, 20:30)) %>%tab_header(title ="Jeu de données 1990-2020 préparé pour {did}",subtitle ="Echantillon des 10 lignes") %>%tab_source_note("Source : Aires protégées d'AP Vahatra, données TMF")
Pour rappel, on récapitule les années d’assignation :
Code
ap_did %>%select(nom, annee_creation) %>%filter(annee_creation >1990) %>%unique() %>%group_by(annee_creation) %>%summarize(`Nombre d'AP créées cette année`=n()) %>%gt() %>%tab_header(title ="Années de création des aires protégées")
Années de création des aires protégées
annee_creation
Nombre d'AP créées cette année
1991
1
1997
9
1998
2
2002
1
2003
1
2004
1
2007
2
2011
2
2012
1
2015
53
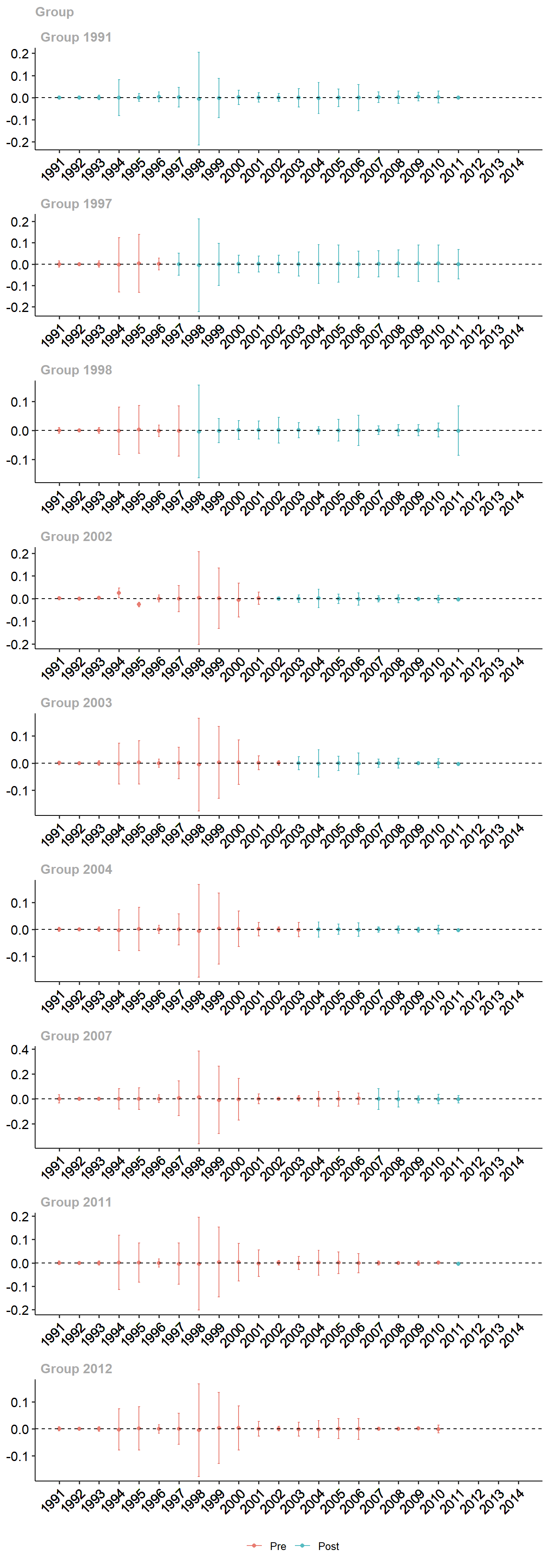
On passe maintenant à l’estimation pour la déforestation.
On aggrège les effets de traitment pour l’ensemble de la période
Code
agg.simple <-aggte(attgt_apmada_def, type ="simple", na.rm =TRUE)summary(agg.simple)
Call:
aggte(MP = attgt_apmada_def, type = "simple", na.rm = TRUE)
Reference: Callaway, Brantly and Pedro H.C. Sant'Anna. "Difference-in-Differences with Multiple Time Periods." Journal of Econometrics, Vol. 225, No. 2, pp. 200-230, 2021. <https://doi.org/10.1016/j.jeconom.2020.12.001>, <https://arxiv.org/abs/1803.09015>
ATT Std. Error [ 95% Conf. Int.]
-0.0001 0.001 -0.0021 0.0019
---
Signif. codes: `*' confidence band does not cover 0
Control Group: Not Yet Treated, Anticipation Periods: 0
Estimation Method: Doubly Robust
Code
# gt(summary(agg.simple)) %>%# tab_header(title = "Effet aggrégé pour les traités de 1991 à 2011") %>%# tab_footnote("Résultats encore préliminaire à confirmer (erreurs possibles)")
Pour la déforestation, on ne voit aucun effet net des aires protégées (ATT très faible et non significativement différent de 0). Mais la taille de l’échantillon est extrêmement restreinte et il est on ne peut pas vraiment en tirer d’interprétation.
Mise en garde : l’échantillon utilisé à titre d’exemple ici est trop petit pour cette méthode. Il convient de préférer une analyse avec un plus grand nombre d’observation, par exemple en se focalisant sur des pixels ou des cellules.
10.3 Application aux données par mailles
L’analyse reposant par aire protégée rassemble un nombre trop faible d’observations. On va donc procéder en réalisant l’analyse par maille. On va donc avoir une observation par hexagone de 5 km2, pour lequel on dispose du couvert forestier par année, de l’année de création de l’aire protégée. La première analyse est une première régression simple n’incluant pas de variables de contrôle. On commence par visualiser les tendances.
Code
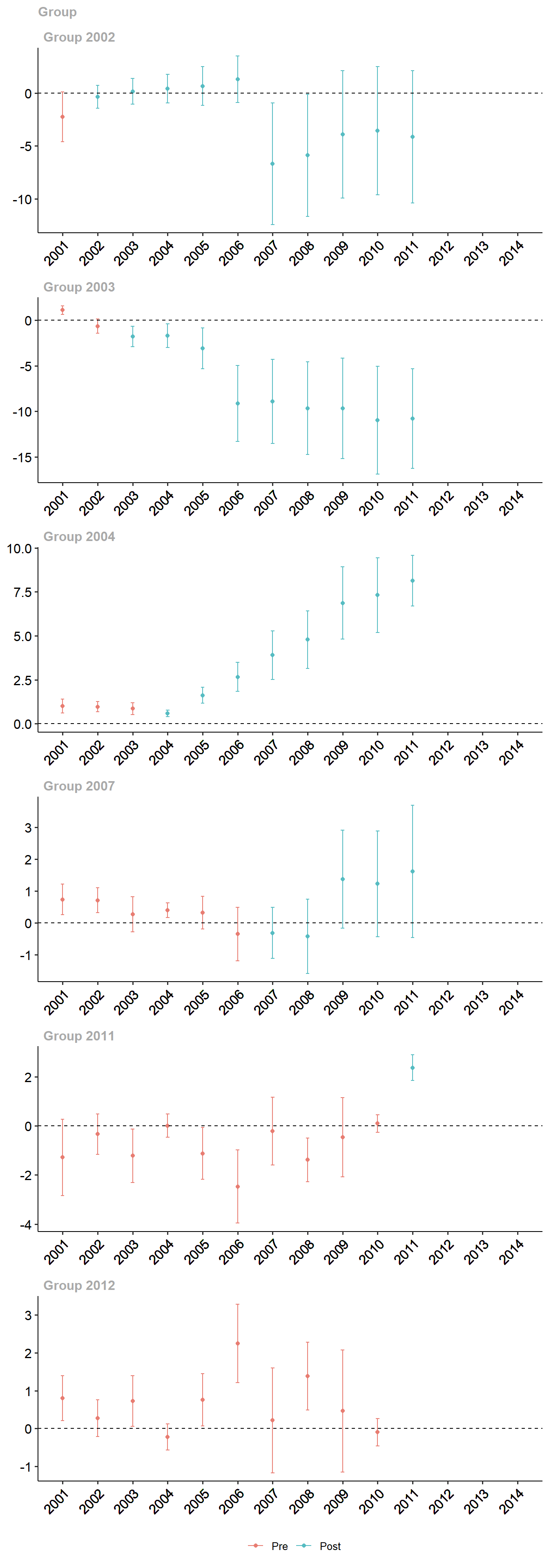
library(sf)load("data/grille_mada_AP.rds") # On charge les données préparées au chapitre 4# On "déplie" les données de déforestation, ce qui produit un format longgrille_mada_AP_long <- grille_mada_AP %>%unnest(cols = treecover_area_and_emissions)# On passe ces paramètres au package didatt_mailles_def <-att_gt(yname ="treecover",tname ="years",idname ="assetid",gname ="an_creation",data = grille_mada_AP_long,control_group ="notyettreated")# On visualise les résultats.ggdid(att_mailles_def) +theme(axis.text.x =element_text(angle =45, hjust =1))
On aggrège à nouveau les résultats de traitements pour l’ensemble de la période, ce qui produit le résumé suivant.
Code
agg.simple <-aggte(att_mailles_def, type ="simple", na.rm =TRUE)summary(agg.simple)
Call:
aggte(MP = att_mailles_def, type = "simple", na.rm = TRUE)
Reference: Callaway, Brantly and Pedro H.C. Sant'Anna. "Difference-in-Differences with Multiple Time Periods." Journal of Econometrics, Vol. 225, No. 2, pp. 200-230, 2021. <https://doi.org/10.1016/j.jeconom.2020.12.001>, <https://arxiv.org/abs/1803.09015>
ATT Std. Error [ 95% Conf. Int.]
-3.4758 0.7226 -4.8921 -2.0595 *
---
Signif. codes: `*' confidence band does not cover 0
Control Group: Not Yet Treated, Anticipation Periods: 0
Estimation Method: Doubly Robust
Les résultats indiquent une baisse de la déforestation. TODO : coefficents à interpréter.
10.4 Doubles différences échelonnées avec contrôles
L’analyse précédente ne tient pas compte de certains facteurs dont on a vu qu’ils pouvaient influencer à la fois la sélection, mais aussi la déforestation, en particulier l’altitude, la qualité des sols, le temps de parcours à la ville la plus proche, ou encore le caractère accidenté du terrain. On va rajouter ces variables comme contrôles, en continuant à comparer les aires protégées créées avant 2015 avec celles créées en 2015.
Code
# On passe ces paramètres au package didatt_mailles_def_crtl <-att_gt(yname ="treecover",tname ="years",idname ="assetid",gname ="an_creation",xformla =~ distance_minutes_5k_110mio + mean_clay_5_15cm + tri_mean + elevation_mean,data = grille_mada_AP_long,control_group ="notyettreated")# On visualise les résultats.ggdid(att_mailles_def_crtl) +theme(axis.text.x =element_text(angle =45, hjust =1))
On aggrège les résultats.
Code
agg.simple <-aggte(att_mailles_def_crtl, type ="simple", na.rm =TRUE)summary(agg.simple)
Call:
aggte(MP = att_mailles_def_crtl, type = "simple", na.rm = TRUE)
Reference: Callaway, Brantly and Pedro H.C. Sant'Anna. "Difference-in-Differences with Multiple Time Periods." Journal of Econometrics, Vol. 225, No. 2, pp. 200-230, 2021. <https://doi.org/10.1016/j.jeconom.2020.12.001>, <https://arxiv.org/abs/1803.09015>
ATT Std. Error [ 95% Conf. Int.]
-2.2241 1.1701 -4.5176 0.0693
---
Signif. codes: `*' confidence band does not cover 0
Control Group: Not Yet Treated, Anticipation Periods: 0
Estimation Method: Doubly Robust
L’ajout des quatre variables de contrôle (temps de trajet à une ville, altitude, caractère accidenté du terrain et teneur en argile du sol) réduit l’effet moyen sur les traités (ATT) estimé et conduit l’intervalle de confiance à englober 0, ce qui nous empêche de conclure avec assurance à la présence d’effets significatifs.
On doit toutefois souligner : 1) Qu’on s’appuie ici sur les données GFC et qu’on ne dispose donc de recul que depuis 2000, à la différence des données TMF qui démarrent en 1990, avec toutefois une fiabilité limitée pour la première décennie ; 2) que la méthode prenant comme contrefactuel les zones situées dans des aires protégées en 2015 réduit la taille d’échantillon et la période d’observation, par opposition à l’approche consistant à utiliser comme contrefactuel des zones non traitées, par exemples celles désignées par matching dans le [Chapitre Chapter 8
Une autre solution consisterait à utiliser des matching pour utiliser comme contrefactuel des zones hors aires protégées.