On commence ici par une approche naïve, dans le sens où on apparie simplement les zones dans les aires protégées avec les zones hors aires protégées pour expliquer le principe du matching (“appariement”, en français).
Les données ne peuvent pas contenir de données manquantes sur les variables d’appariement, donc on les écarte.
Code
library(tidyverse)library(MatchIt)library(stargazer)library(sf)library(cobalt)library(tmap)# Taille des titres des cartestaille_titres_cartes =1load("data/grille_mada_summary_AP.rds")# On référence le nom des variables qui vont servir à l'analysevariables_analyse <-c("assetid","treatment","distance_minutes_5k_110mio","tri_mean", "elevation_mean", "mean_clay_5_15cm","treecover_2000", "var_treecover")# On renomme le ficher 'df' (dataframe) : plus concis dans les commandes ensuitedf <- grille_mada_summary_AP %>%# On supprime toutes les lignes pour lesquelles au moins 1 valeur variable # est manquante parmi les variables d'analysemutate(treatment = position_ap =="Intérieur") %>%drop_na(any_of(variables_analyse))
On analyse maintenant le score de propension.
Code
# Get propensity scoresglm_out <-glm(treatment ~ distance_minutes_5k_110mio + mean_clay_5_15cm + tri_mean + elevation_mean + treecover_2000, family =binomial(link ="probit"),data = df)cellmatch_out1 <-stargazer(glm_out,summary =TRUE,type ="html",title ="Probit regression for matching frame ") %>%str_replace_all("\\*", "\\\\*") # Dans un bloc plus bas et non affiché, on a le code suivant# cat(cellmatch_out1)
Probit regression for matching frame
Dependent variable:
treatment
distance_minutes_5k_110mio
0.0004***
(0.00003)
mean_clay_5_15cm
-0.042***
(0.002)
tri_mean
0.015***
(0.001)
elevation_mean
0.0003***
(0.00002)
treecover_2000
0.002***
(0.00004)
Constant
-1.449***
(0.043)
Observations
117,610
Log Likelihood
-23,367.050
Akaike Inf. Crit.
46,746.090
Note:
*p<0.1; **p<0.05; ***p<0.01
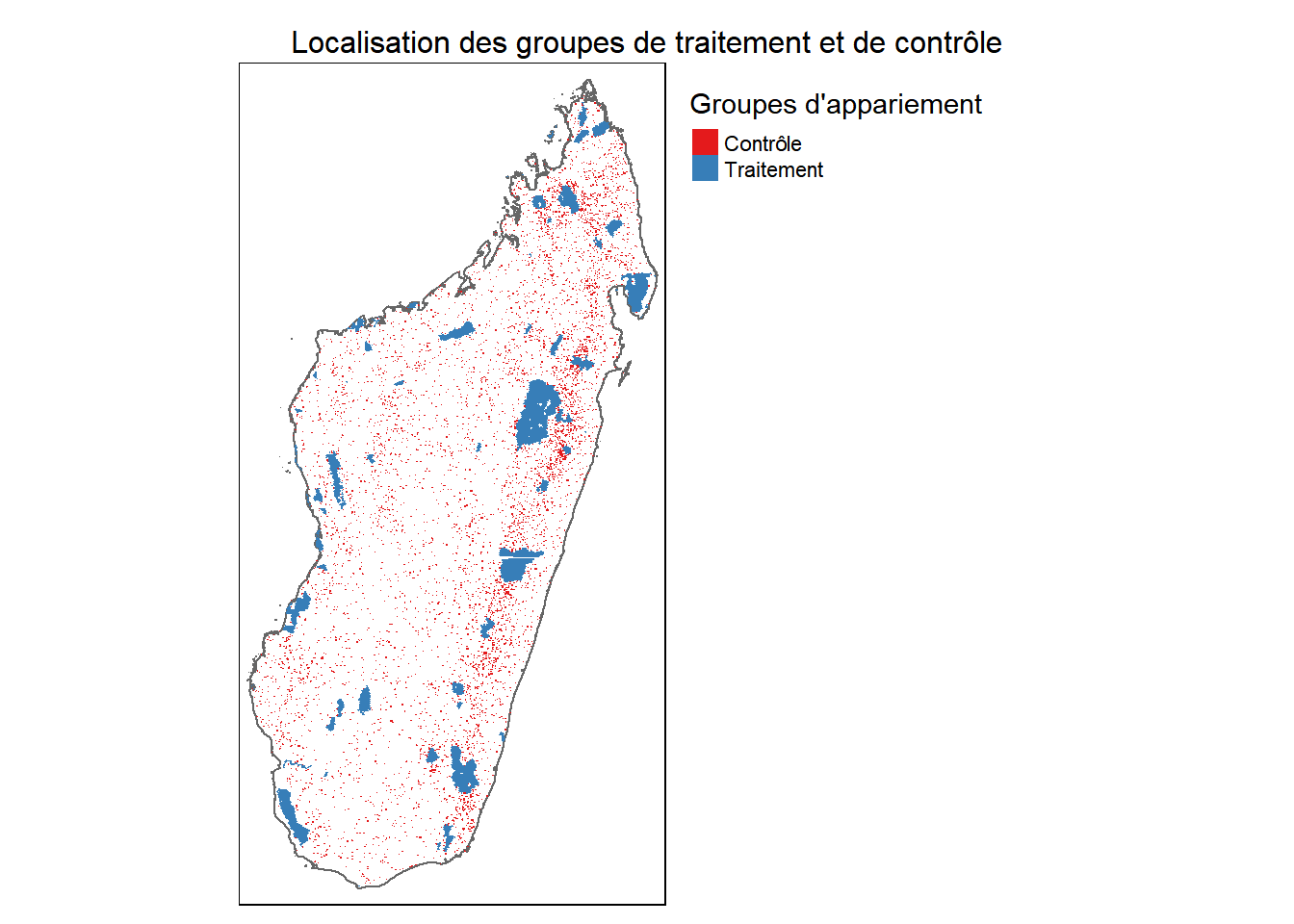
On visualise la localisation des cellules utilisées comme contrôles.
Code
m_out <-matchit(treatment ~ distance_minutes_5k_110mio + mean_clay_5_15cm + tri_mean + elevation_mean + treecover_2000,data = df,method ="nearest",replace =TRUE,# exact = ~ as.factor(NAME_0),distance ="glm", discard ="both", # common support: drop units from both groups link ="probit")print(m_out)
A matchit object
- method: 1:1 nearest neighbor matching with replacement
- distance: Propensity score [common support]
- estimated with probit regression
- common support: units from both groups dropped
- number of obs.: 117610 (original), 12731 (matched)
- target estimand: ATT
- covariates: distance_minutes_5k_110mio, mean_clay_5_15cm, tri_mean, elevation_mean, treecover_2000
Code
# print(summary(m_out, un = FALSE))bal_table <-bal.tab(m_out, un =TRUE)print(bal_table)
m_data <-match.data(m_out) %>%st_sf()# On charge le countour des frontières malgachesload("data/contour_mada.rds")# On visualise les données appareilléestm_shape(contour_mada) +tm_borders() +tm_shape(m_data) +tm_fill(col ="treatment", palette ="Set1", title ="Groupes d'appariement",labels =c("Contrôle", "Traitement")) +tm_layout(legend.outside =TRUE,main.title ="Localisation des groupes de traitement et de contrôle",main.title.position =c("center", "top"),main.title.size = taille_titres_cartes)
On réalise la régression.
Code
modele <-lm(formula = var_treecover ~ treatment + distance_minutes_5k_110mio + mean_clay_5_15cm + tri_mean + elevation_mean + treecover_2000,data = m_data,weights = weights)cellmatch_out2 <-stargazer(modele, type ="html") %>%str_replace_all("\\*", "\\\\*") # Dans un bloc plus bas et non affiché, on a le code suivant# cat(cellmatch_out2)