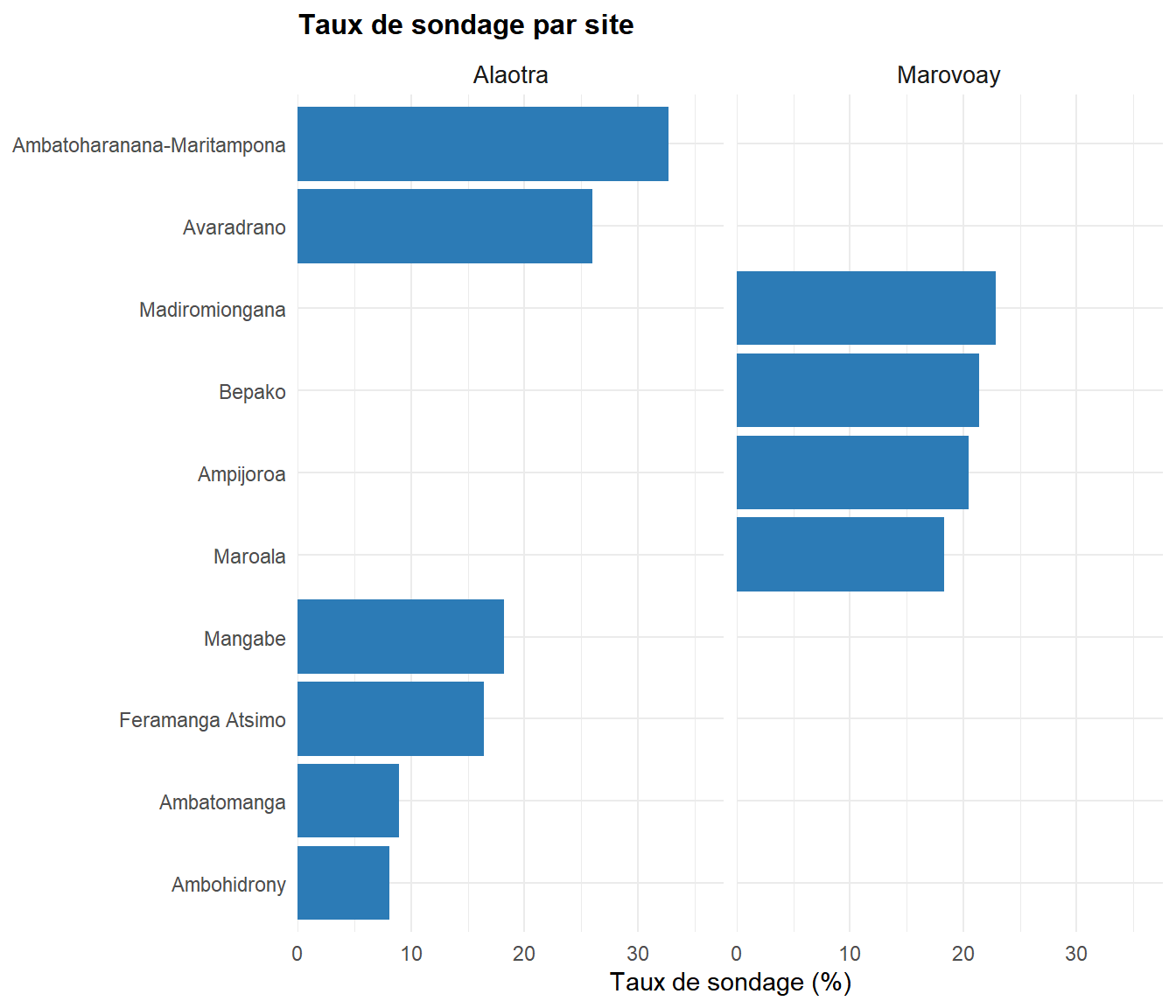
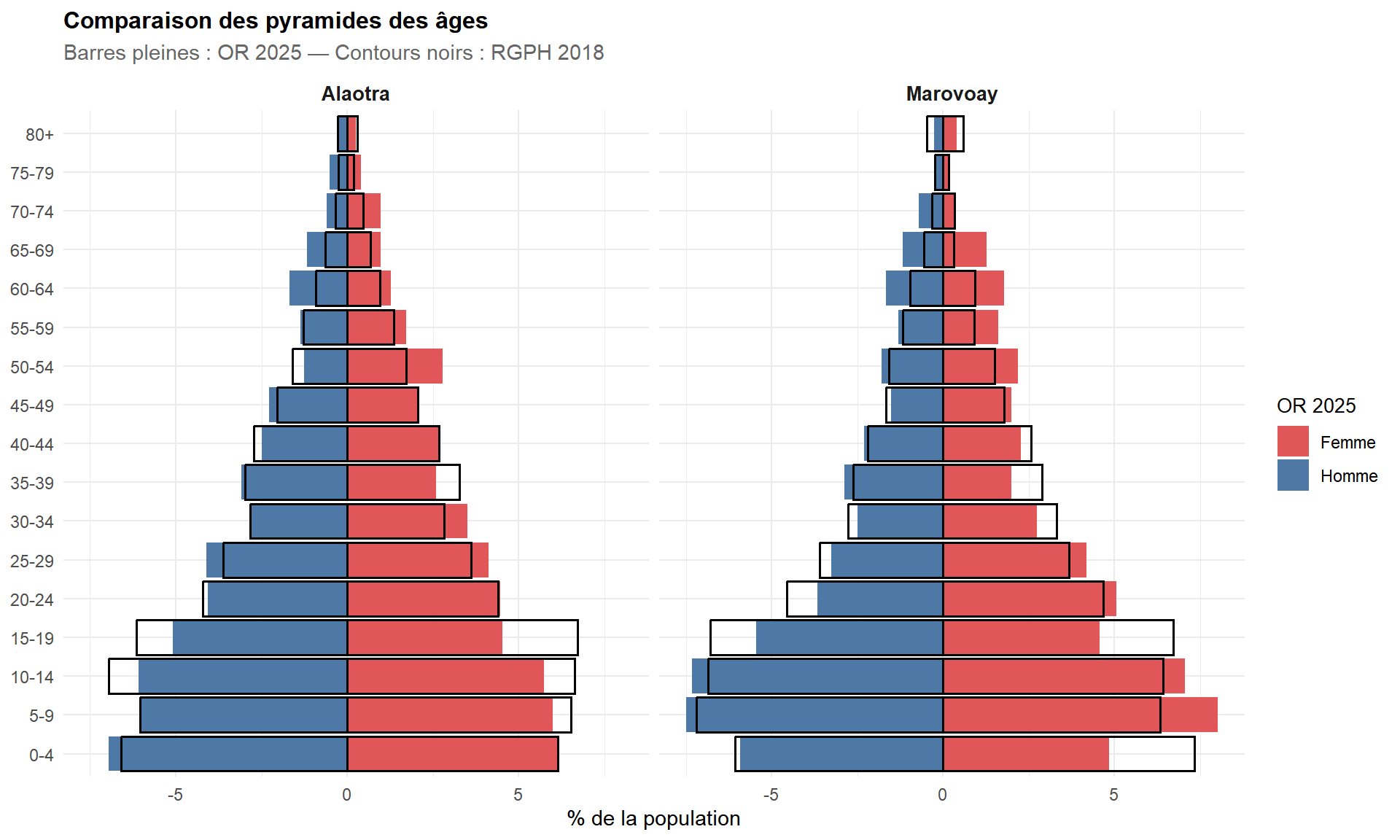
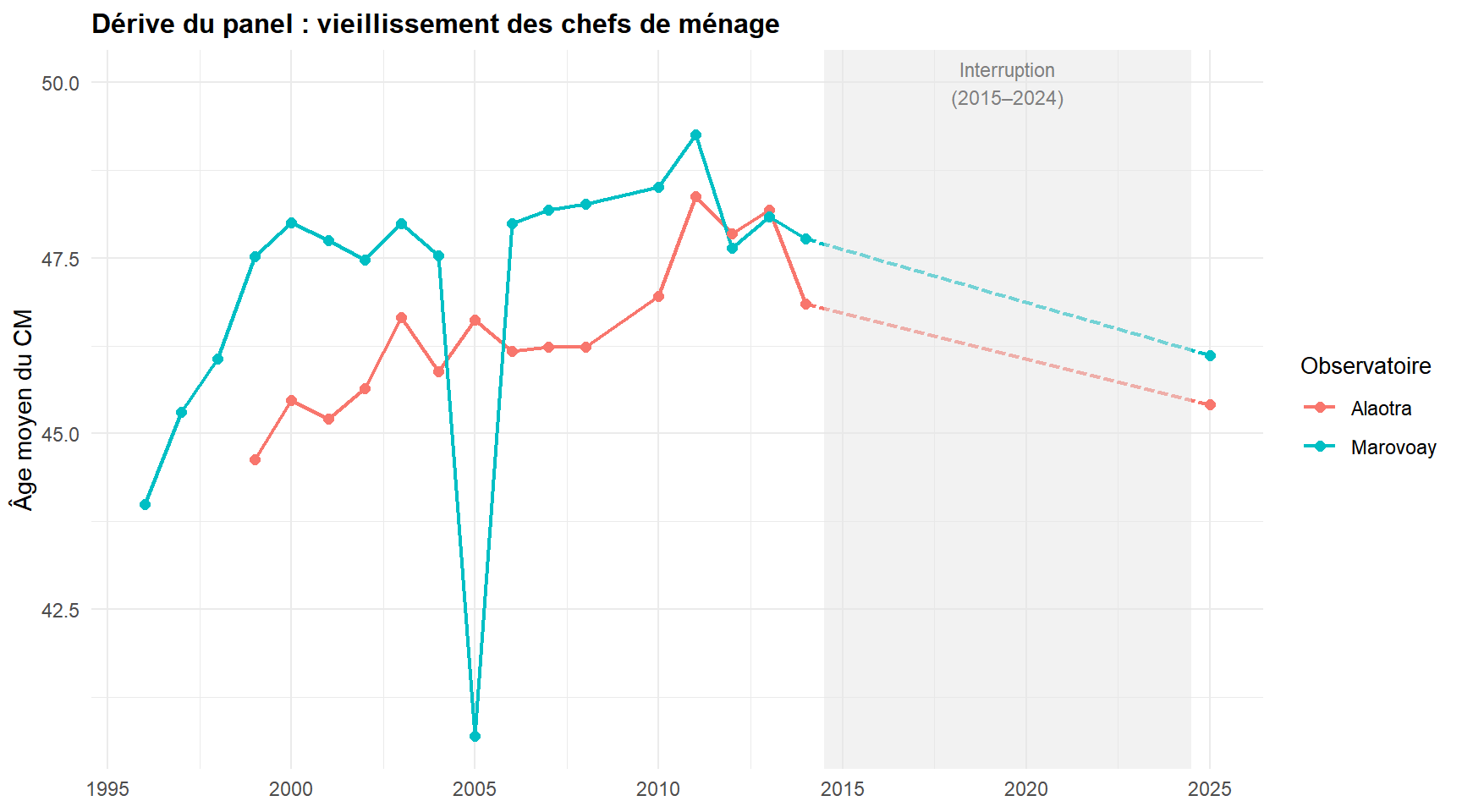
codes_communes <- read.csv(
"data/RGPH_2018_Madagascar/data/codes_communes_mg.csv"
)
# --- Correspondance site → commune (depuis le dénombrement nettoyé) ---
site_commune_map <- enum_all |>
mutate(
site_key = case_when(
Observatory == "Alaotra" &
Fokontany %in% c("Analamiranga", "Maritampona") ~
"ambatoharanana-maritampona",
TRUE ~ normalize_name(Fokontany)
)
) |>
filter(!is.na(Commune)) |>
distinct(site_key, Commune, Observatory)
# --- Crosswalk commune OR → RGPH (gestion des casses et orthographes) ---
commune_xwalk_tbl <- tribble(
~Commune, ~Commune_RGPH,
"Ambohiboromanga", "AMBOHIBOROMANGA",
"Morarano Chrome", "MORARANO CHROME",
"Ilafy", "ILAFY",
"Feramanga Nord", "FERAMANGE NORD",
"Amparafaravola", NA_character_,
"Tsararano", "TSARARANO",
"Ankazomborona", "ANKAZOMBORONA",
"Antanimasaka", "ANTANIMASAKA"
)
# --- RGPH stats par commune ---
commune_rgph <- rgph_res_or |>
left_join(
codes_communes |> rename(COMMUNES = CODECOM, Commune_RGPH = COMMUNEARRONDISSEMENT),
by = "COMMUNES"
) |>
summarise(
Rés_RGPH = n(),
Mén_RGPH = n_distinct(IDMEN),
Taille_RGPH = round(n() / n_distinct(IDMEN), 1),
Fem_RGPH = round(mean(as.numeric(P05) == 2, na.rm = TRUE) * 100, 1),
Âge_RGPH = round(mean(as.numeric(P08), na.rm = TRUE), 1),
.by = c(Observatory, COMMUNES, Commune_RGPH)
) |>
arrange(Observatory, COMMUNES)
# --- OR stats par commune ---
or_commune_hh <- res_m_a |>
count(j5, Observatory, name = "taille") |>
left_join(
res_deb |>
mutate(
j4_norm = normalize_name(j4),
site_key = case_when(
Observatory == "Marovoay" ~
str_extract(j4_norm, str_c(mr_sites, collapse = "|")),
Observatory == "Alaotra" ~
al_j4_fkt$site_key[match(j4_norm, al_j4_fkt$j4_norm)]
)
) |>
select(j5, site_key),
by = "j5"
) |>
left_join(site_commune_map |> select(site_key, Commune), by = "site_key")
commune_or <- or_commune_hh |>
filter(!is.na(Commune)) |>
summarise(
Mén_OR = n_distinct(j5),
Taille_OR = round(mean(taille), 1),
.by = c(Observatory, Commune)
)
or_commune_indiv <- res_m_a |>
left_join(
res_deb |>
mutate(
j4_norm = normalize_name(j4),
site_key = case_when(
Observatory == "Marovoay" ~
str_extract(j4_norm, str_c(mr_sites, collapse = "|")),
Observatory == "Alaotra" ~
al_j4_fkt$site_key[match(j4_norm, al_j4_fkt$j4_norm)]
)
) |>
select(j5, site_key),
by = "j5"
) |>
left_join(site_commune_map |> select(site_key, Commune), by = "site_key") |>
filter(!is.na(Commune))
commune_or2 <- or_commune_indiv |>
summarise(
Rés_OR = n(),
Fem_OR = round(mean(m4 == 2, na.rm = TRUE) * 100, 1),
Âge_OR = round(mean(m5, na.rm = TRUE), 1),
.by = c(Observatory, Commune)
)
commune_or_full <- commune_or |>
left_join(commune_or2, by = c("Observatory", "Commune")) |>
left_join(commune_xwalk_tbl, by = "Commune")
# --- Tableau combiné via crosswalk ---
commune_stats <- commune_rgph |>
full_join(
commune_or_full,
by = c("Observatory", "Commune_RGPH")
) |>
mutate(Commune = coalesce(Commune, Commune_RGPH)) |>
filter(!is.na(Commune_RGPH) | !is.na(Mén_OR))
commune_stats |>
select(Observatory, Commune, Rés_RGPH, Mén_RGPH, Taille_RGPH, Fem_RGPH, Âge_RGPH,
Rés_OR, Mén_OR, Taille_OR, Fem_OR, Âge_OR) |>
obs_gt() |>
cols_label(
Commune = "Commune",
Rés_RGPH = "Rés.", Mén_RGPH = "Mén.", Taille_RGPH = "Taille",
Fem_RGPH = "% fem.", Âge_RGPH = "Âge moy.",
Rés_OR = "Rés.", Mén_OR = "Mén.", Taille_OR = "Taille",
Fem_OR = "% fem.", Âge_OR = "Âge moy."
) |>
tab_spanner(label = "RGPH 2018",
columns = c(Rés_RGPH, Mén_RGPH, Taille_RGPH, Fem_RGPH, Âge_RGPH)) |>
tab_spanner(label = "OR 2025",
columns = c(Rés_OR, Mén_OR, Taille_OR, Fem_OR, Âge_OR)) |>
fmt_number(columns = c(Fem_RGPH, Âge_RGPH, Fem_OR, Âge_OR), decimals = 1) |>
sub_missing(missing_text = "—") |>
tab_source_note(
source_note = md("**Sources** : RGPH-3 2018 (échantillon 10 %, milieu rural) ; Enquête OR 2025.<br>
Le site d'Ambatoharanana-Maritampona correspond à la commune d'Amparafaravola,<br>
qui n'apparaît pas dans les données rurales du RGPH.")
) |>
style_table()